Let’s see how to use redisson as a distributed locking strategy for several instances that have a critical section, like writing to a file, plus some tips to avoid blocking the main-thread (the source of the evil)….
Lock
With java we have many classes to apply some kind of lock, even the simplest and infamous synchronize type.
synchonize(this) {
//sección critica
}I prefer something that unlocks the main thread faster especially for writing. StampeLock is also uncomplicated, unlike using a AtomicReference although many say the opposite, also ReentrantReadWriteLock has its resemblance to Stamped.
The actual code and what it does
This project stream-function-samples-consumer-producer inspired by previous work on dlq by Oleg Zhurakousky

We have a producer that with configuration of ThreadPoolTaskExecutor via configuration will adjust the number of threads for the producer. (ProducerTaskExecutor-N, la N is the number of the Thread), at the time of sending with the spring cloud stream we add the timestamp at that time with System.currentTimeMillis this message will arrive at a queue called performance-queue, then the message will be processed by the number of consumers we have, they will calculate the total sending time, and write it in HH:mm;latency format in a file that is in the NAS.
| This is an old version of the code, and at the end of the code we use the method onSpinWait |
private void sendMessage(final String input, final long delay, final long docCount, String message) {
log.info("Enviando mensaje con delay de {} ms para docCount {}", delay, docCount);
MessageDto messageDto = new MessageDto();
messageDto.setMessage(message);
for (int index = 0; index < docCount; index++) {
System.out.println("Uppercasing " + input + " " + Thread.currentThread().getName());
// var stamped = STAMPED_LOCK.writeLock();
//
// try {
Message<MessageDto> messageToSend = MessageBuilder.withPayload(messageDto)
.setHeader("timeStamp", System.currentTimeMillis())
.build();
this.streamBridge.send(PERFORMANCE_QUEUE, messageToSend);
if (input.equals("fail")) {
System.out.println("throwing exception");
throw new RuntimeException("Itentional");
}
// } finally {
// STAMPED_LOCK.unlockWrite(stamped); (1)
// }
try {
Thread.sleep(delay);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}| 1 | Caution must be taken here, when doing send and apply a lock, in version 3 of spring cloud stream, which is the one I have in the example, if we do locking avoid creating channels in the producer, the ideal behavior is if we have a number of Threads in the producer will create a channel per Thread. |
| Here we have just one instance, one single channel, one single thread on the producer’s side. |
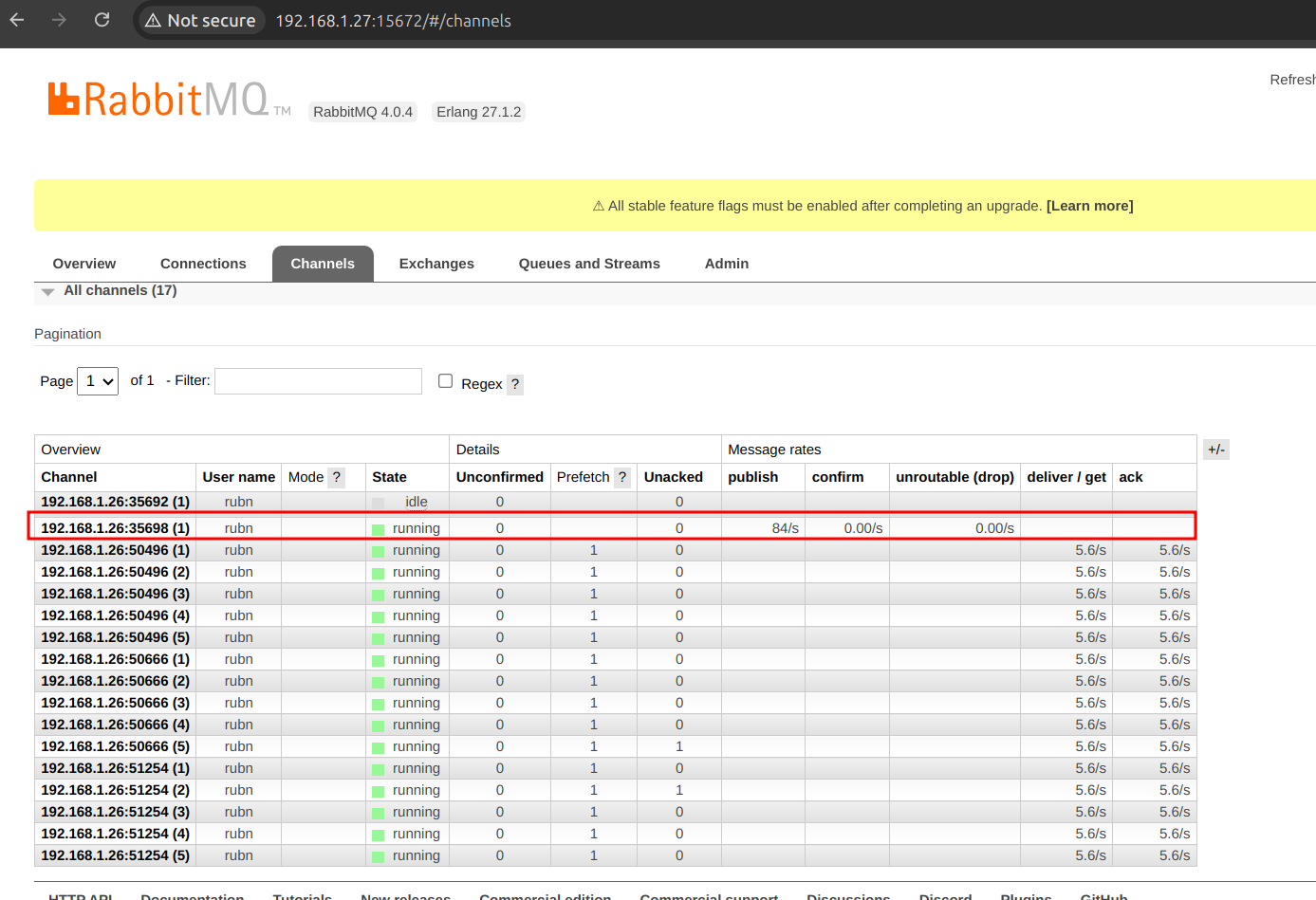
| Here we can already see that when we increase the number of threads, more connections are created. |
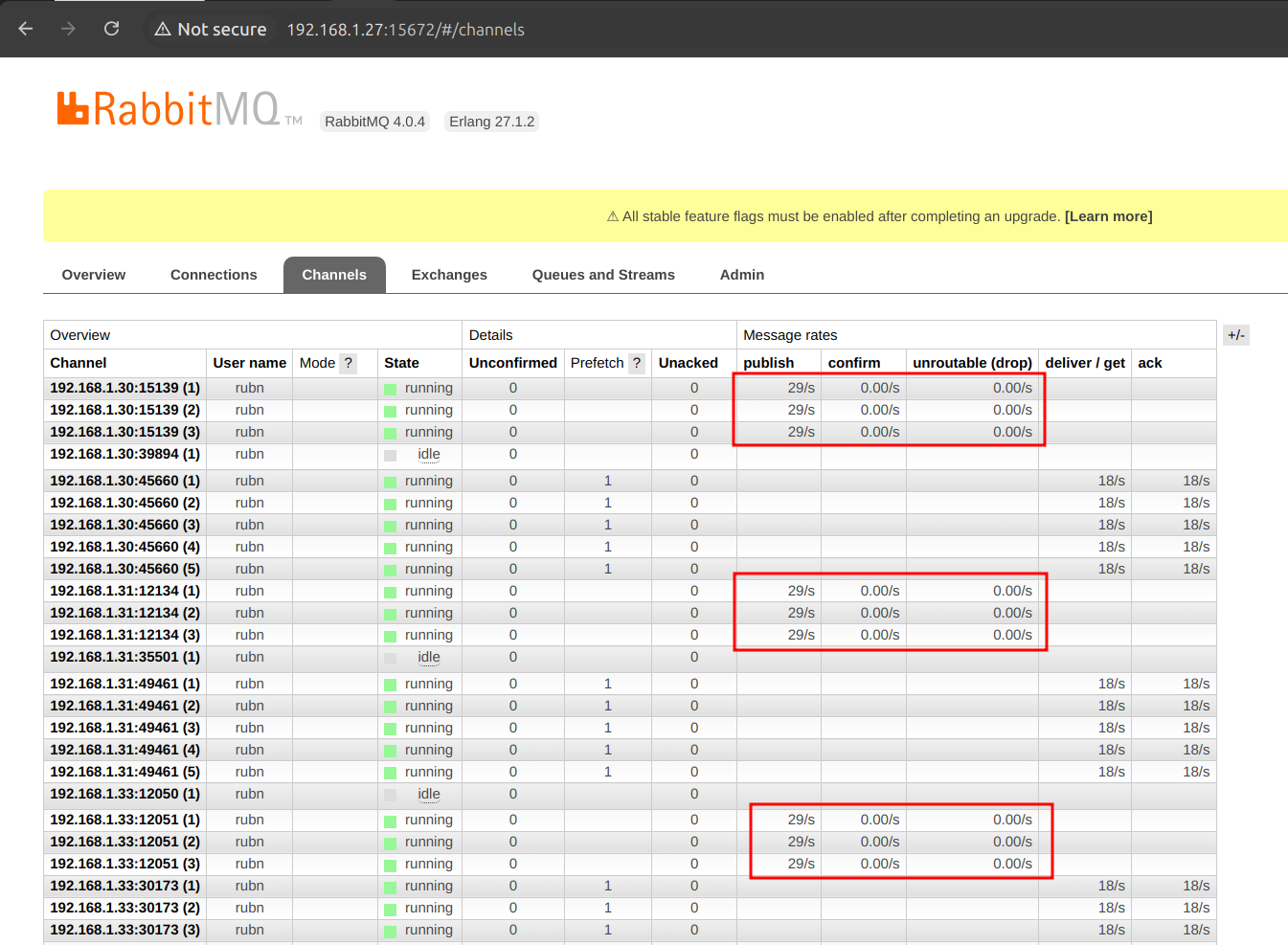
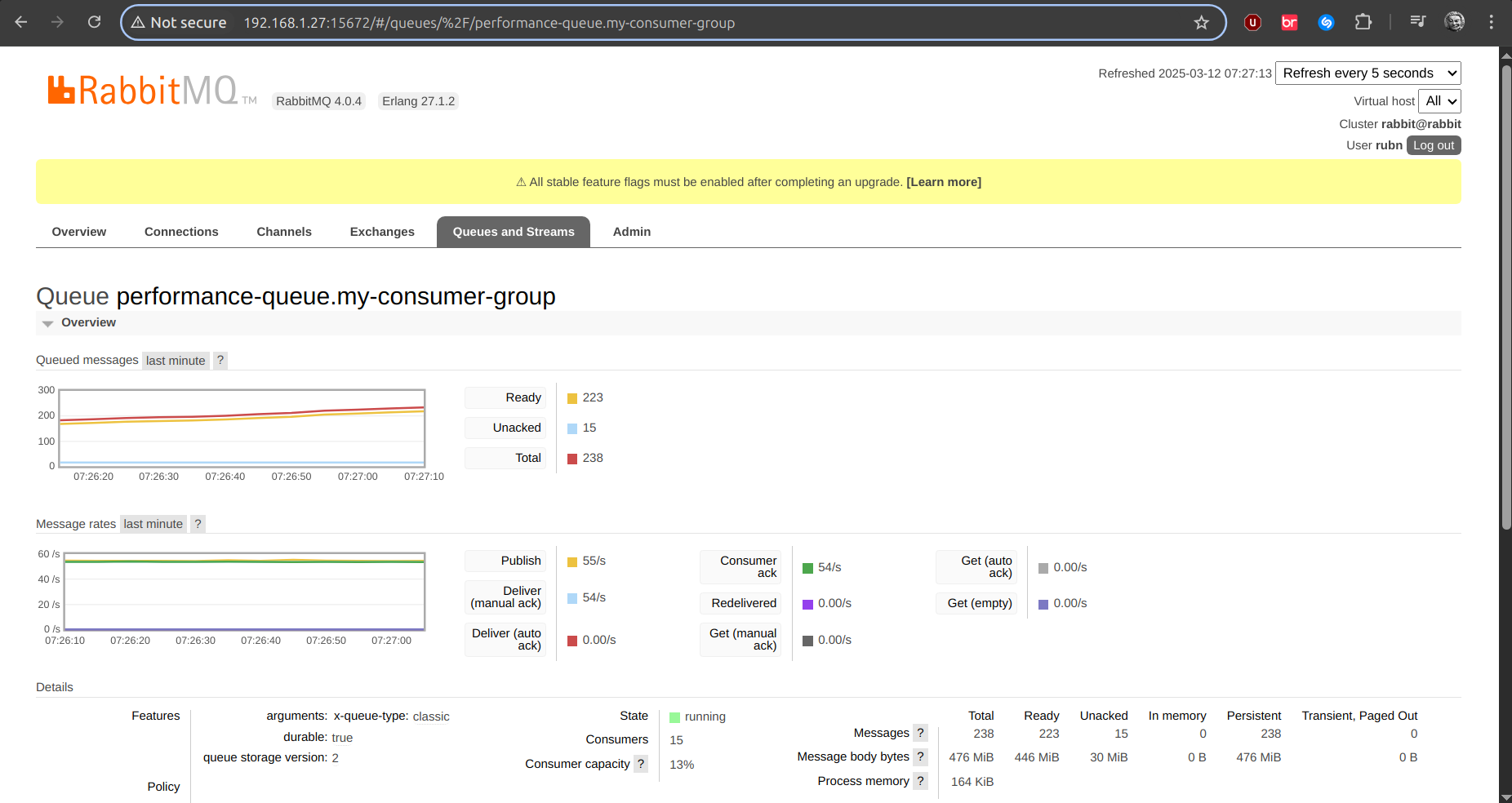
The consumer does not have an explicit ThreadThreadPool applied to it as such, but by means of the configuration of the SCS(spring cloud stream) we increase concurrency, for example:
spring:
cloud:
function:
definition: consumer
stream:
default-binder: rabbit
rabbit:
bindings:
consumer-in-0:
consumer:
prefetch: 1
binders:
rabbit:
type: rabbit
environment:
spring:
rabbitmq:
host: ${URL_BROKER}
port: 5672
username: ${USER}
password: ${PASSWORD}
bindings:
consumer-in-0: # Canal de entrada (Consumidor)
destination: performance-queue
group: my-consumer-group
consumer:
concurrency: 5 # Número de consumidores concurrentes (1)
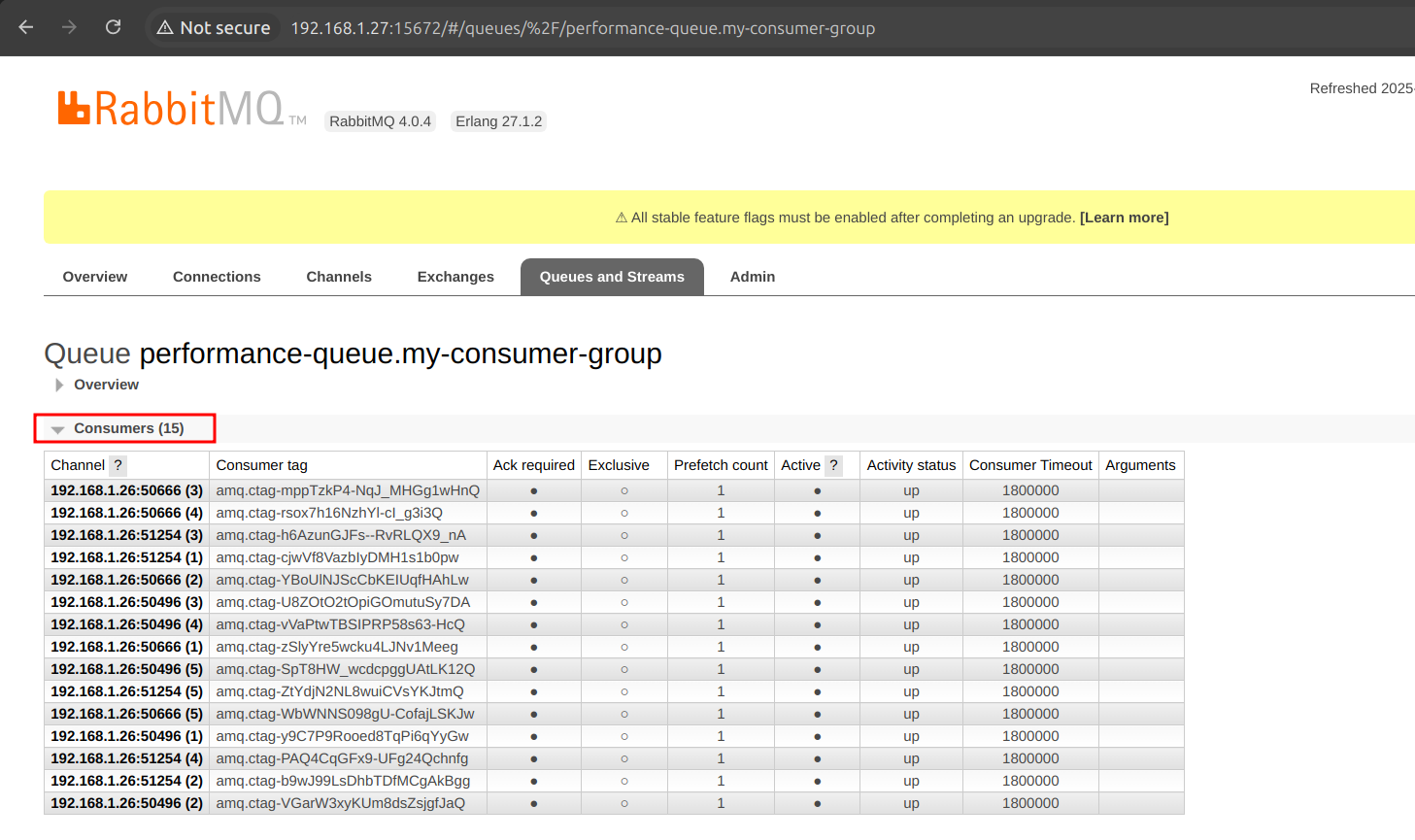
prefetch: 1| 1 | Here we increase the concurrency as such, and in the Rabbit UI you will see the number of consumers, clearly we have 5, but if we have 3 replicas, 15 to be created, as in the following image: |
To create the instances with this Bastillefile will be a little faster, for a java development environment.
PKG -y bash zip unzip curl git nano tmux
# jails.conf
CONFIG set allow.mlock;
CONFIG set allow.raw_sockets;
SYSRC defaultrouter="192.168.1.1"
# Install zsh
PKG zsh
CMD chsh -s /usr/local/bin/zsh root
PKG ohmyzsh
CMD cp /usr/local/share/ohmyzsh/templates/zshrc.zsh-template ~/.zshrc
# zsh-autosuggestions
PKG powerline-fonts zsh-autosuggestions
CMD echo 'source /usr/local/share/zsh-autosuggestions/zsh-autosuggestions.zsh' >> ~/.zshrc
# Install openjdk
PKG openjdk11 openjdk17 openjdk21
# Install sdkman
CMD curl -s "https://get.sdkman.io" | bash
CMD /usr/local/bin/zsh -c "echo 'export SDKMAN_DIR="$HOME/.sdkman"' >> ~/.zshrc"
CMD /usr/local/bin/zsh -c "echo '[[ -s "$HOME/.sdkman/bin/sdkman-init.sh" ]] && source "$HOME/.sdkman/bin/sdkman-init.sh"' >> ~/.zshrc"
# Copy available openjdk to candidates and then remove it
CMD mkdir -p ~/.sdkman/candidates/java
CMD cp -r /usr/local/openjdk11 ~/.sdkman/candidates/java/11
CMD cp -r /usr/local/openjdk17 ~/.sdkman/candidates/java/17
CMD cp -r /usr/local/openjdk21 ~/.sdkman/candidates/java/21
# Create symbolic links before removing packages
CMD ln -s ~/.sdkman/candidates/java/11/bin/java /usr/local/openjdk11/java
CMD ln -s ~/.sdkman/candidates/java/11/bin/javac /usr/local/openjdk11/javac
CMD ln -s ~/.sdkman/candidates/java/17/bin/java /usr/local/openjdk17/java
CMD ln -s ~/.sdkman/candidates/java/17/bin/javac /usr/local/openjdk17/javac
CMD ln -s ~/.sdkman/candidates/java/21/bin/java /usr/local/openjdk21/java
CMD ln -s ~/.sdkman/candidates/java/21/bin/javac /usr/local/openjdk21/javac
CMD pkg remove -y openjdk11 openjdk17 openjdk21
CMD /usr/local/bin/zsh -c "source \$HOME/.sdkman/bin/sdkman-init.sh && sdk install maven"
CMD /usr/local/bin/zsh -c "source \$HOME/.sdkman/bin/sdkman-init.sh && sdk install jbang"
CMD /usr/local/bin/zsh -c "source \$HOME/.zshrc"
# Set default java version to 21
CMD /usr/local/bin/zsh -c "source \$HOME/.sdkman/bin/sdkman-init.sh && sdk default java 21"
CMD /usr/local/bin/zsh -c "rehash"|
tmux in our help for using many windows
|
The problem
3 instances writing to a file a latency (it can be anything), for example, but when the write is performed, something happens between lines like:
| These were the initial latencies, no longer 😂 |
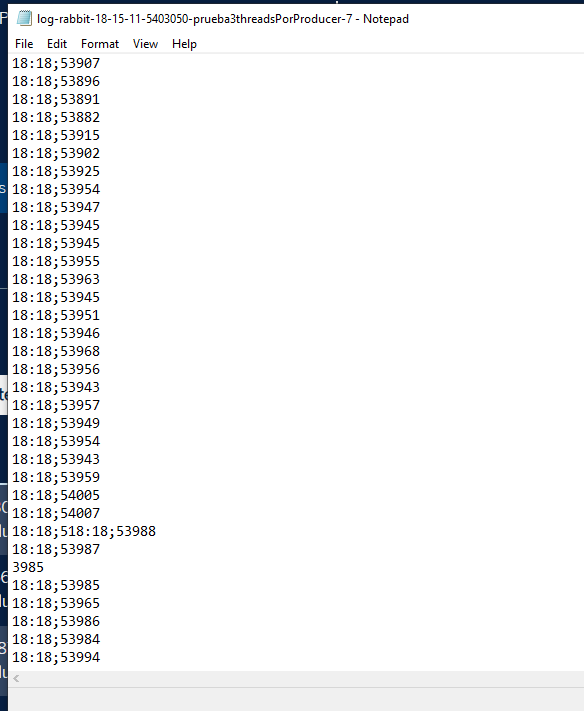
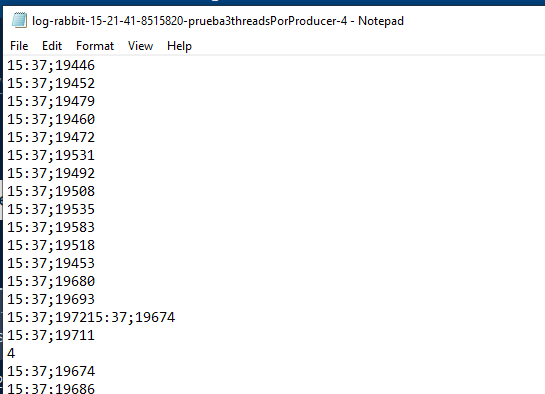
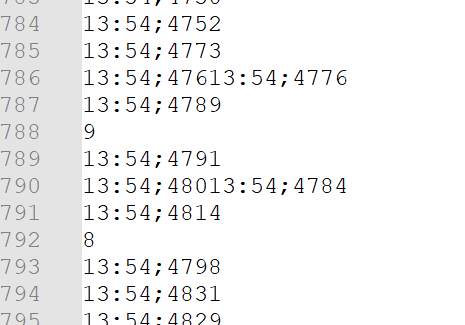
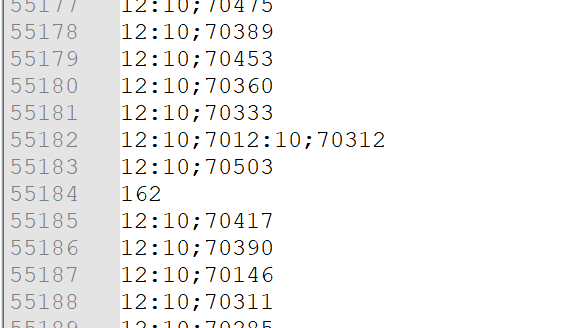
Even if each instance has its own lock, they could still interfere at a certain point as in the cases above, which I do not know whether to consider it a race-condition (I do not believe this case), but still this side effect occurs, the write method of the BuffereWriter contains internally in the jdk11 a synchronize itself as this in the Writer class:
public void write(String str, int off, int len) throws IOException {
synchronized (lock) {
char cbuf[];
if (len <= WRITE_BUFFER_SIZE) {
if (writeBuffer == null) {
writeBuffer = new char[WRITE_BUFFER_SIZE];
}
cbuf = writeBuffer;
} else { // Don't permanently allocate very large buffers.
cbuf = new char[len];
}
str.getChars(off, (off + len), cbuf, 0);
write(cbuf, 0, len);
}
}Installing Redis Server

Redis has a client called Redisson, to abstract all the structures related to redis, one of them is the use of RLock that we will use to test in this case and to be able to remedy our concurrency issue at the time of writing
Con este Bastillefile, lo instalamos
# Install redis
PKG redis
SYSRC redis_enable="YES"
CONFIG set allow.mlock;
CONFIG set allow.raw_sockets;
SYSRC defaultrouter="192.168.1.1"
CMD redis-cli ping (1)| 1 | This should answer PONG on the console |
We are going to edit the redis.conf file that is in the path /usr/local/etc/redis.conf
bind * -::*
requirepass ultrapassword
service redis restart (1)| 1 | Yes, it was necessary to reboot. |
Config para Redisson

The configuration we are going to use in the consumer is the following:
@Configuration
public class ReddisonClientConfiguration {
@Bean
public RedissonClient redissonClient(RedissonCredentialsConfiguration credentialsConfiguration) {
Config config = new Config();
config.useSingleServer().setAddress(credentialsConfiguration.getUrl());
config.useSingleServer().setPassword(credentialsConfiguration.getPassword());
return Redisson.create(config);
}
}| Now with the RLock for the critical section, practically the same story as with the StampedLock, things are looking a little better: |
private void writeLine(BufferedWriter writer, long latency) throws IOException {
final RLock lock = redissonClient.getLock("logFileLock");
lock.lock();
try {
//HH:mm;latency
final String line = FORMATER.format(LocalTime.now()) + ";" + latency;
writer.write(line);
writer.newLine();
} finally {
lock.unlock();
}
}
This video was sent 100 m/s messages per second
|
{
"values": [
{
"dato": 1,
"doc_count": 6000
},
{
"dato": 2,
"doc_count": 6000
},
{
"dato": 3,
"doc_count": 6000
},
{
"dato": 4,
"doc_count": 6000
},
{
"dato": 5,
"doc_count": 6000
},
{
"dato": 6,
"doc_count": 6000
},
{
"dato": 7,
"doc_count": 6000
},
{
"dato": 8,
"doc_count": 6000
},
{
"dato": 9,
"doc_count": 6000
},
{
"dato": 10,
"doc_count": 6000
}
]
}There is no overlap, or strange lines in the little .txt file, not bad I think, also if the thing gets too complicated, each instance can write in its own file.
Avoiding contention in the main-thread
Well, this part is also the hardest part of the test, introducing threads and adding a Thread.sleep(), and then even worse, expecting good or regular performance and even more in a low latency app.
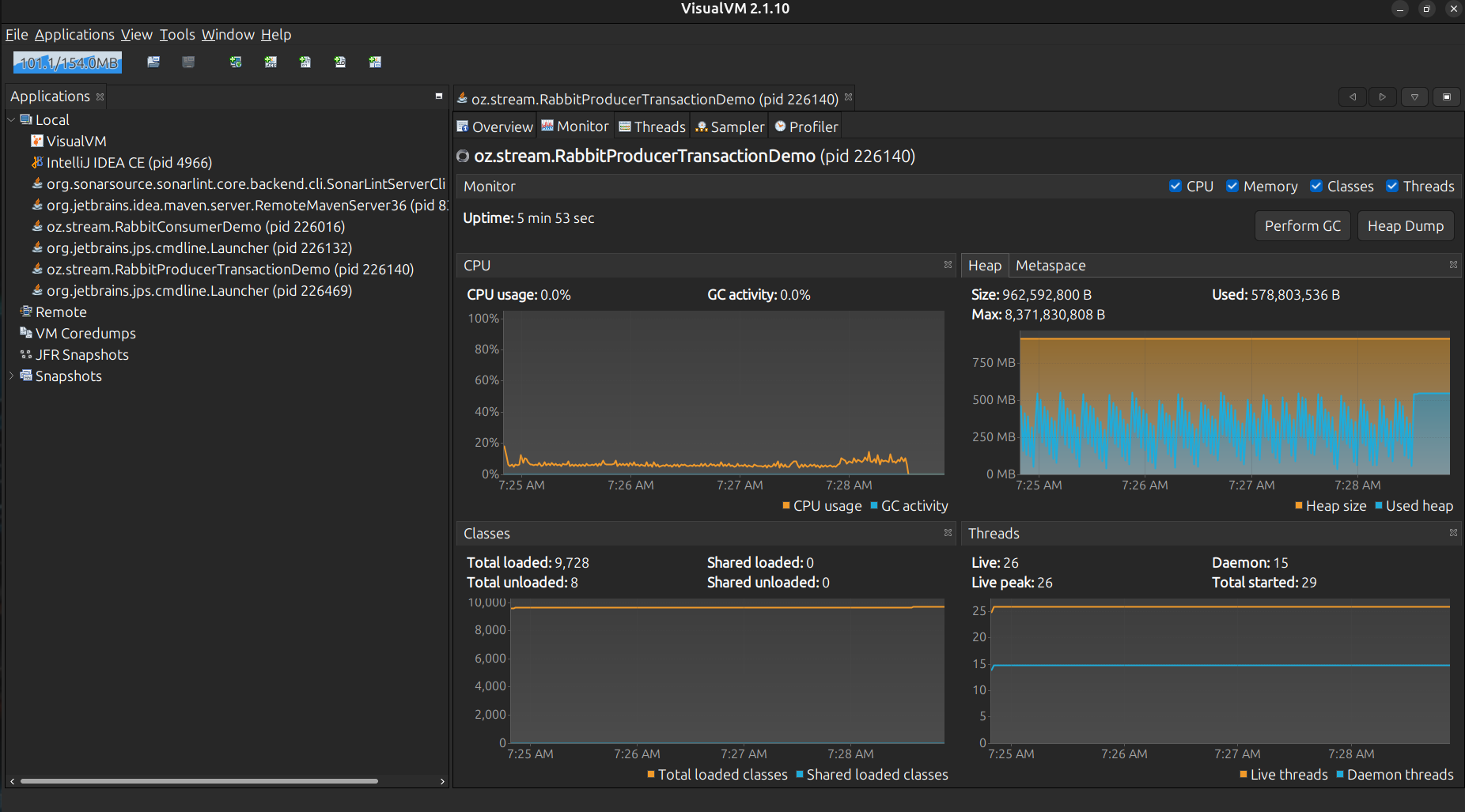
The previous code, we had Thread.sleep() right in the main thread to adjust the message rate, each paused thread for that, placing it in sleeping state to running and vice versa, these states as Park, Running, Wait, Monitor, Sleeping, we can see them more comfortably with the JVisualVM, the Java-Mission-Control highly recommended as well.
The idea is to tune our app, visualizing its behavior in real time, and watch how the threads behave, the sleep() is blocking and simply adds contention, reducing the throughput performance in the long run for example:
Looking at some approaches
These tests, depending on the environment, can vary a lot, since messages of different sizes are sent, the hardware, etc…
On the producer’s side:
-
200KiB messages.
-
3 Threads.
-
100msg/sec must be sent.
On the consumer side:
-
Loading into memory and then writing to disk when the producer’s shipment is complete.
-
15 Threads.
sendMessage con Thread.onSpinWait()
for (int index = 0; index < totalDocCountToProcess; index++) {
// We try to obtain the following available time slot
// maintains overall rhythm between Threads, no context switching
long currentSlot;
long nextSlot;
do {
currentSlot = lastGlobalSendTime.get();
nextSlot = currentSlot + globalDelayPerMessage;
} while (!lastGlobalSendTime.compareAndSet(currentSlot, nextSlot)); //CAS
// We wait until it is our turn
while (System.nanoTime() < nextSlot) {
Thread.onSpinWait();
}
Message<MessageDto> messageToSend = MessageBuilder.withPayload(messageDto)
.setHeader("timestamp_ms", System.currentTimeMillis())
.build();
this.streamBridge.send(PERFORMANCE_QUEUE, messageToSend);
COUNTER.incrementAndGet();
}Here are 3 Threads called RabbitProducerTaskExecutor-N, and will always be running is ideal, small delays are applied with onSpinWait and an AtomicLong, increasing performance considerably, and making it send a more stable and accurate message rate.
With this approach, the 100msgsec is more stable.
sendMessage con Thread.sleep()
for (int index = 0; index < totalDocCountToProcess; index++) {
Message<MessageDto> messageToSend = MessageBuilder.withPayload(messageDto)
.setHeader("timestamp_ms", System.currentTimeMillis())
.build();
this.streamBridge.send(PERFORMANCE_QUEUE, messageToSend);
COUNTER.incrementAndGet();
try {
Thread.sleep(TimeUnit.NANOSECONDS.toMillis(globalDelayPerMessage)); (1)
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}| 1 | The nanos are passed to millis which is what sleep() needs. |
It can be seen that now the Threads are more in sleeping than in running, and some times, they pass to running state but very little, this is equal to little performance and not stable with the onSpinWait or active waiting, busy-waiting.
With the sleep() to reach 100msg/sec it costs a lot of time
sendMessage con schedule()
@Configuration
public class SpringAsyncConfig {
private static final AtomicInteger THREAD_COUNTER = new AtomicInteger();
@Bean
public ScheduledExecutorService scheduledExecutorService(AppConfiguration configuration) {
final ThreadFactory threadFactory = runnable -> {
final Thread thread = new Thread(runnable);
thread.setName("RabbitProducerExecutor-" + THREAD_COUNTER.incrementAndGet());
return thread;
};
return Executors.newScheduledThreadPool(configuration.getCorePoolSize(), threadFactory);
}
}...
final CountDownLatch countDownLatch = new CountDownLatch((int) totalMessages);
for (int index = 0; index < numThreads; index++) {
// Si hay resto, algunos threads envían un mensaje extra
final long messagesForThisThread = messagesPerThread + (index < remainder ? 1 : 0);
scheduledExecutorService.schedule(() -> {
this.sendMessage(globalDelayPerMessage, messagesForThisThread, message, countDownLatch);
}, 0, TimeUnit.MICROSECONDS); (1)
}
try {
countDownLatch.await();
} catch (InterruptedException ex) {
throw new RuntimeException(ex);
}
log.info("Envío completado. Tiempo total: {} Total docCount: {}", responseTimeService.formatResponseTime(), COUNTER.get());
...
for (int index = 0; index < totalDocCountToProcess; index++) {
this.scheduledExecutorService.schedule(() -> {
Message<MessageDto> messageToSend = MessageBuilder.withPayload(messageDto)
.setHeader("timestamp_ms", System.currentTimeMillis())
.build();
this.streamBridge.send(PERFORMANCE_QUEUE, messageToSend);
COUNTER.incrementAndGet();
countDownLatch.countDown();
}, globalDelayPerMessage * index, TimeUnit.NANOSECONDS); (2)
}| 1 | On zero, so that the task is triggered quickly. |
| 2 | Here, if we set the delay and multiply it by each index. |
With the newScheduledThreadPool you can appreciate a better performance than the version where we use the sleep(), and the states of the Threads vary a little more, from Running to Sleeping, Monitor, even Park as well, being the code a little simpler than using CAS + onSpinWait().
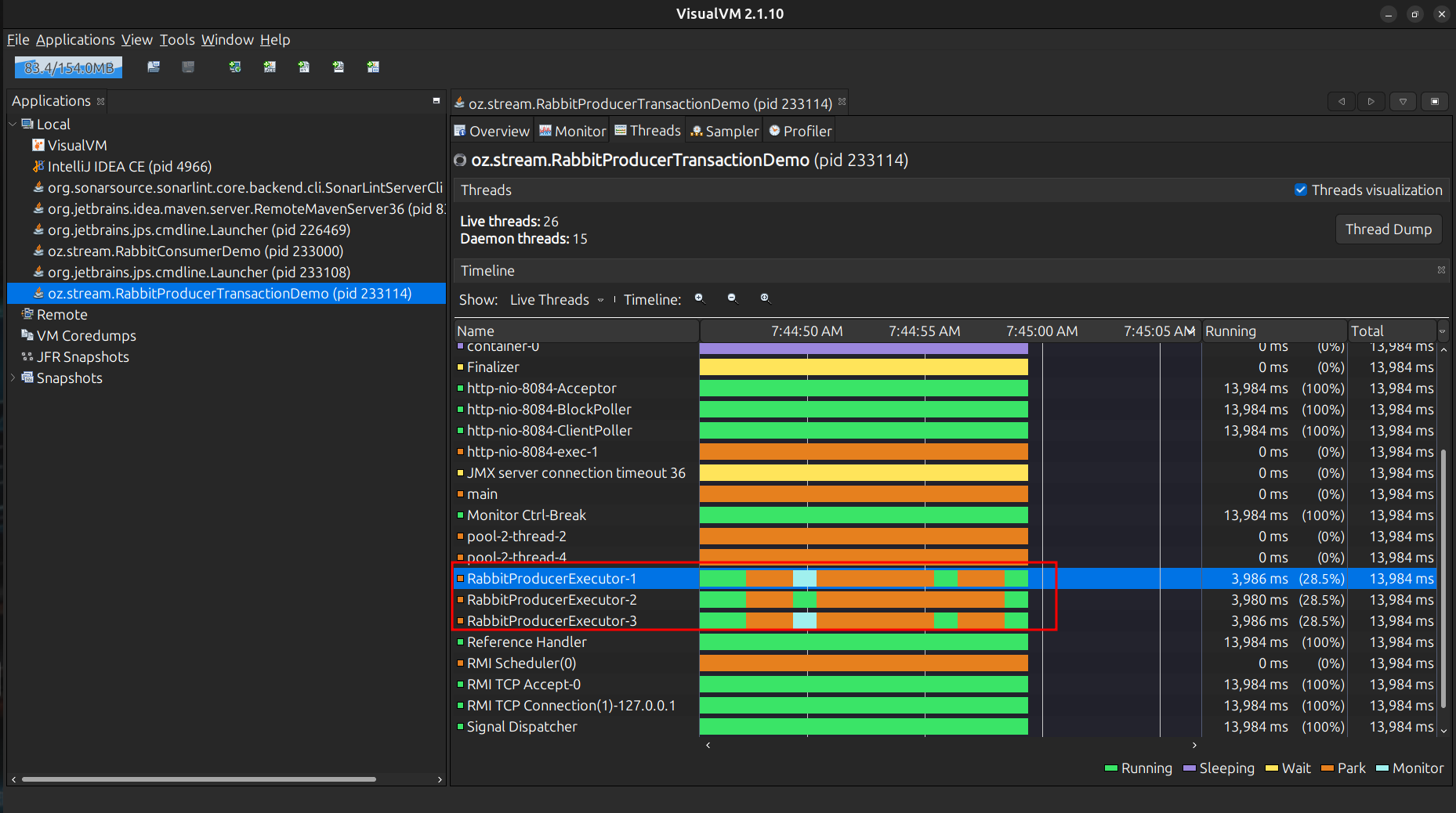
sendMessage with a reactive stream
public Scheduler scheduler() {
final AtomicInteger atomicInteger = new AtomicInteger(0);
final ThreadFactory threadFactory = runnable -> {
final Thread thread = new Thread(runnable);
thread.setName("RabbitProducerMessage-" + atomicInteger.incrementAndGet()); (1)
return thread;
};
return Schedulers.fromExecutor(Executors.newFixedThreadPool(3, threadFactory));
}| 1 | The customized name of our Thread, RabbitProducerMessage- |
@Test
@SneakyThrows
@DisplayName("Emiting 30 items/messages in total")
void reactiveMessageSenderStepVerifier() {
final var counter = new AtomicInteger(0);
StepVerifier.create(Flux.range(0, 3)
.publishOn(this.scheduler())
.flatMap(mapper -> Flux.range(0, 10)
.delayElements(Duration.ofMillis(33))
.publishOn(this.scheduler())
.doOnNext(onNext -> {
counter.incrementAndGet();
log.info("Send message {}", "ABC");
})
))
.expectNextCount(30) (1)
.verifyComplete();
}| 1 | We make sure to issue 30 test itemsmessages, to ensure that the reactive stream works as it should. |
@Configuration
public class SpringAsyncConfig {
@Bean
public Scheduler scheduler(AppConfiguration configuration) {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(configuration.getCorePoolSize()); // Minimum number of threads in the pool
executor.setThreadNamePrefix("RabbitProducerTaskExecutor-"); // Prefix for thread names
executor.initialize(); // Initializes the thread pool
return Schedulers.fromExecutor(executor);
}
}Flux.range(0, numThreads)
.flatMap(index -> {
final long messagesForThisThread = messagesPerThread + (index < remainder ? 1 : 0);
return this.sendMessage(globalDelayPerMessage, messagesForThisThread, message, countDownLatch);
})
.subscribe();
try {
countDownLatch.await();
} catch (InterruptedException ex) {
throw new RuntimeException(ex);
}
log.info("Envío completado. Tiempo total: {} Total docCount: {}", responseTimeService.formatResponseTime(), COUNTER.get());private Mono<Void> sendMessage(final long globalDelayPerMessage, final long totalDocCountToProcess,
String messagePayload, final CountDownLatch countDownLatch) {
log.info("Iniciando envío de {} mensajes con un delay de {} ms", totalDocCountToProcess, TimeUnit.NANOSECONDS.toMillis(globalDelayPerMessa
MessageDto messageDto = new MessageDto();
messageDto.setMessage(messagePayload);
return Flux.range(0, (int) totalDocCountToProcess)
.delayElements(Duration.ofMillis(globalDelayPerMessage))
.publishOn(this.scheduler) (1)
.doOnNext(this.getTimestampMs(messageDto))
.then()
.doOnTerminate(countDownLatch::countDown);
}
private Consumer<Integer> getTimestampMs(MessageDto messageDto) {
return onNext -> {
Message<MessageDto> messageToSend = MessageBuilder.withPayload(messageDto)
.setHeader("timestamp_ms", System.currentTimeMillis())
.build();
this.streamBridge.send(PERFORMANCE_QUEUE, messageToSend);
COUNTER.incrementAndGet();
};
}| 1 | These items change their execution in our custom executor. |
Here the thing varies a little, with the range operator, we iterate also by the number of current threads, important the publishOn operator to execute the internal items in our customized executor.
Messages from 2MiB
You see differences here, but the CPU consumption is not that much by the looks of it.
Already with messages heavier than 2MiB with the onSpintWait, it also suffers.
We even see in console
Envío completado. Tiempo total: 5(min) 329(sec) 329349(ms) 2147483647(nanos) Total docCount: 18000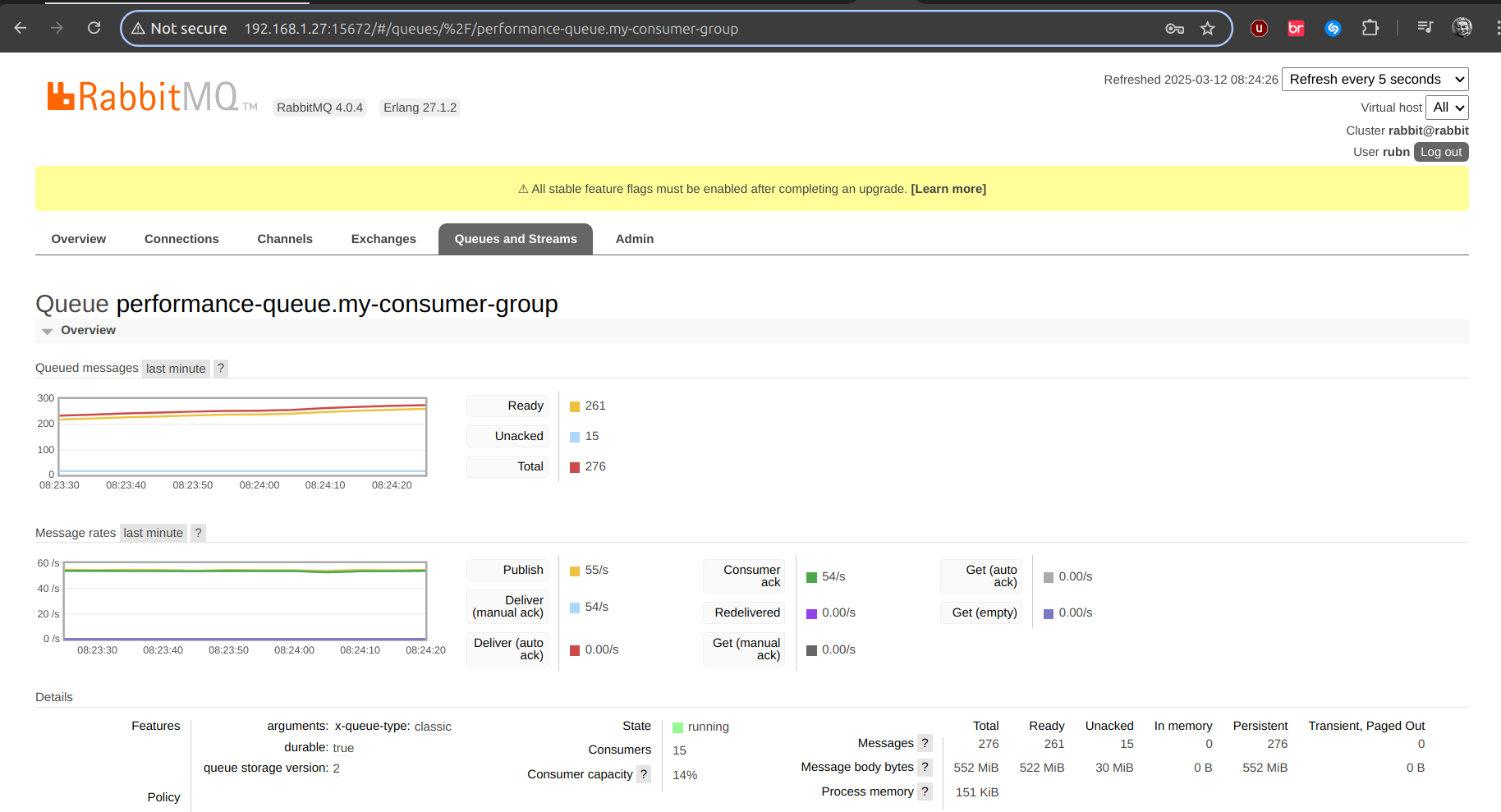
CPU Consumption
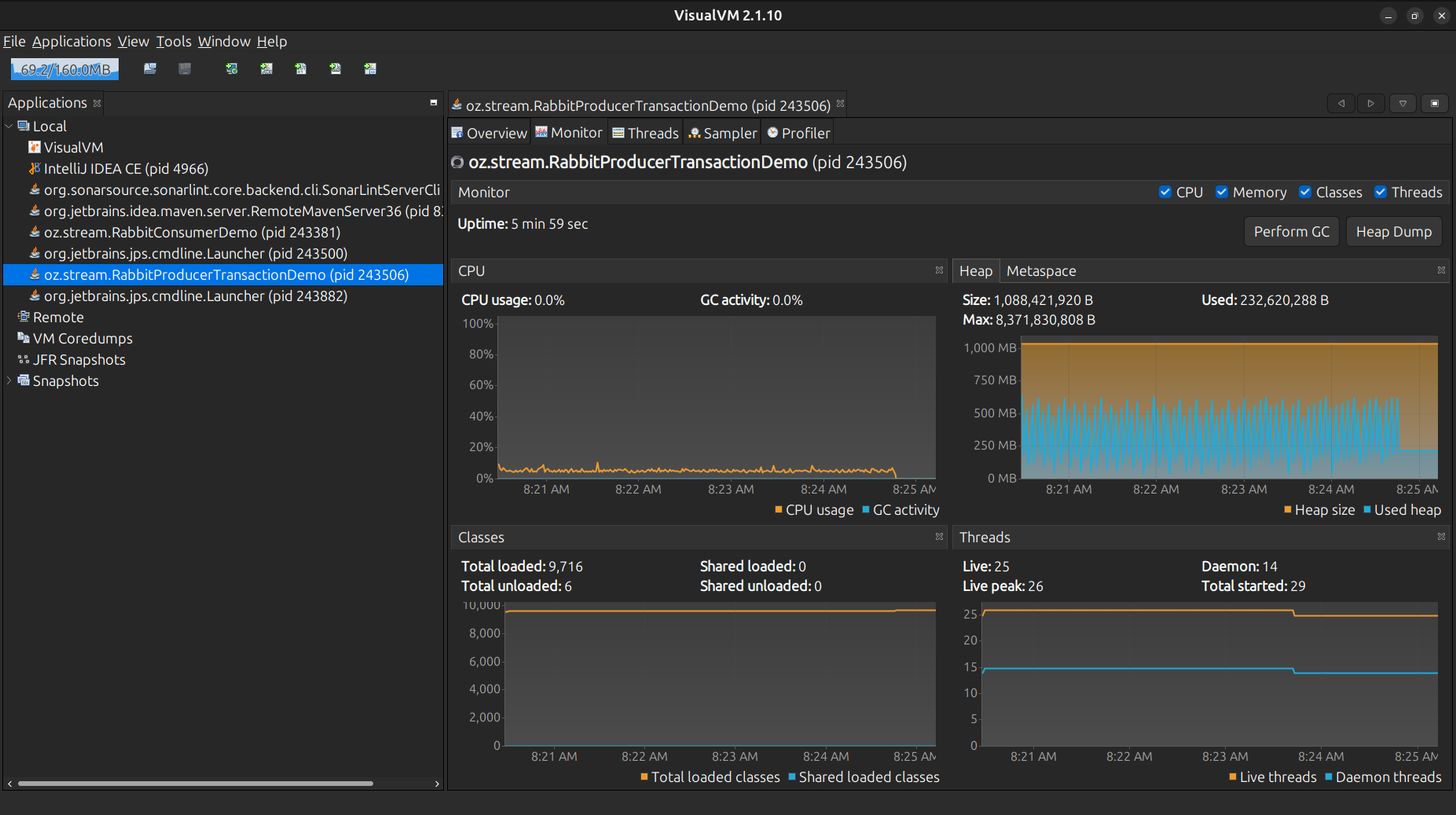
Already here the amount of gluing is higher, and increasing…
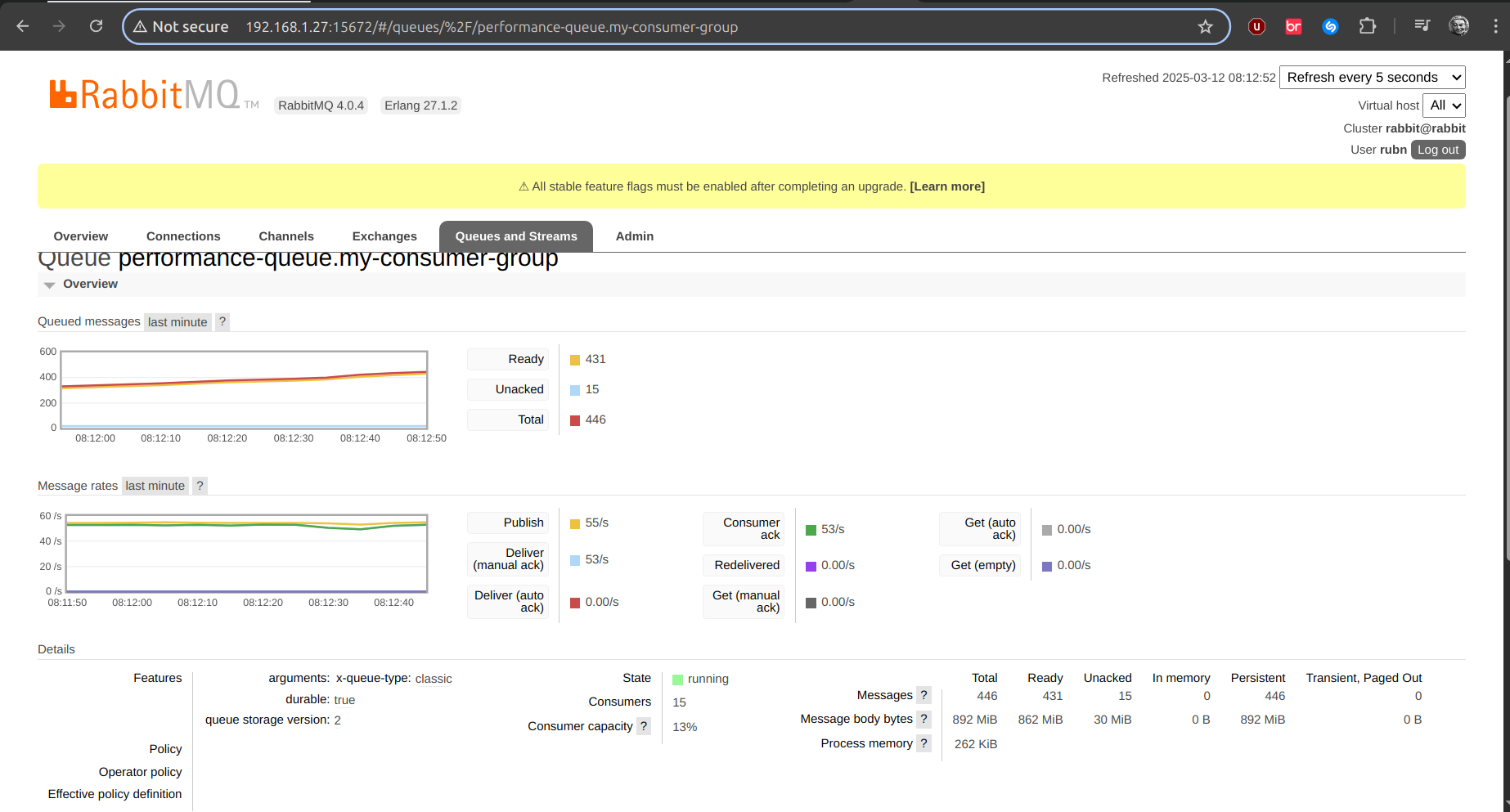
CPU Consumption
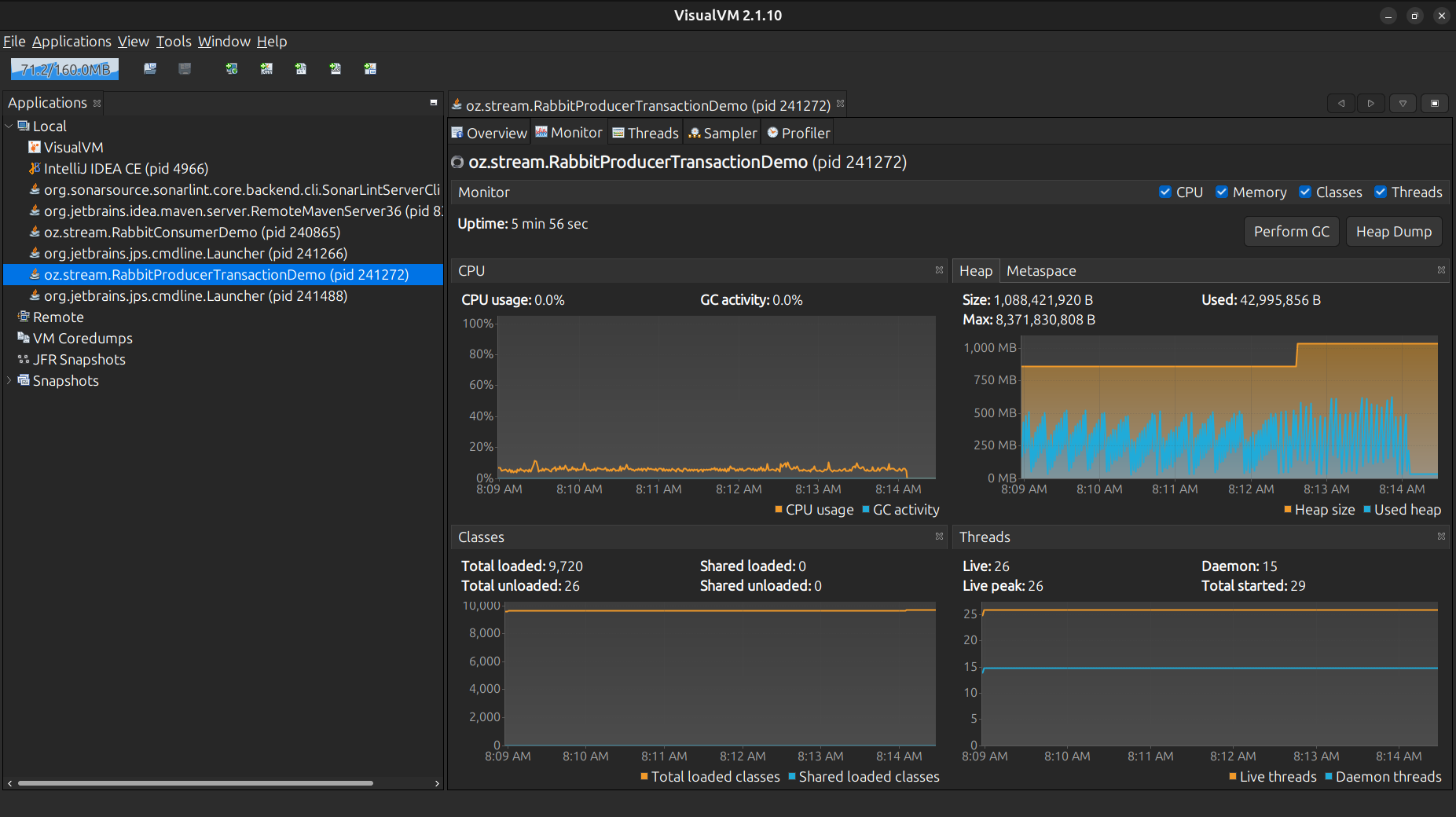
With the ScheduledExecutorService more messages can be queued.
CPU Consumption