Vamos a ver como usar redisson como estrategia de lock distribuido para varias instancias que tienen un sección crítca, como escritura en un fichero, además alguno que otro tip para evitar bloquear el main-thread (el origen del mal)…
Lock
Con java tenemos muchas clases para aplicar algún tipo de lock, incluso la más simple e infame synchronize típo
synchonize(this) {
//sección critica
}Yo prefiero algo que desbloque el main thread más rápido sobre todo para escritura el StampeLock de esta manera tampoco es complicado, a diferencia de usar un AtomicReference, aunque muchos dicen lo inverso, también ReentrantReadWriteLock tiene su parecido al Stamped.
| Esta versión de codigo es vieja, ya finalizando se hace uso del método onSpinWait |
El código actual y que hace
Este proyecto stream-function-samples-consumer-producer inspirando en un trabajo previo sobre dlq de Oleg Zhurakousky

Tenemos un productor que con configuración de ThreadPoolTaskExecutor via configuración se ajustaran el número de threads para el productor (ProducerTaskExecutor-N, la N es el numero del Thread) , al momento de enviar con el método send de spring cloud stream añadimos el timestamp en ese momento con System.currentTimeMillis dicho mensaje llegara a una cola llamada performance-queue, luego el mensaje se procesara por la cantidad de consumidores que tengamos, estos calcularán el tiempo total de envío, y lo escribiran en formado HH:mm;latency en un fichero que esta en el NAS.
private void sendMessage(final String input, final long delay, final long docCount, String message) {
log.info("Enviando mensaje con delay de {} ms para docCount {}", delay, docCount);
MessageDto messageDto = new MessageDto();
messageDto.setMessage(message);
for (int index = 0; index < docCount; index++) {
System.out.println("Uppercasing " + input + " " + Thread.currentThread().getName());
// var stamped = STAMPED_LOCK.writeLock();
//
// try {
Message<MessageDto> messageToSend = MessageBuilder.withPayload(messageDto)
.setHeader("timeStamp", System.currentTimeMillis())
.build();
this.streamBridge.send(PERFORMANCE_QUEUE, messageToSend);
if (input.equals("fail")) {
System.out.println("throwing exception");
throw new RuntimeException("Itentional");
}
// } finally {
// STAMPED_LOCK.unlockWrite(stamped); (1)
// }
try {
Thread.sleep(delay);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}| 1 | Hay que tener precaución aquí, al hacer send y aplicar un lock, en la versión 3 de spring cloud stream, que es la que tengo en el ejemplo,
si hacemos locking evitara crear channels en el productor, el comportamiendo ideal, es si tenemos un número de Threads en el productor se creara un channel por Thread. |
| justamente aqui tenemos por prueba una instancia, un solo canal/channel, un solo Thread por parte del producer. |
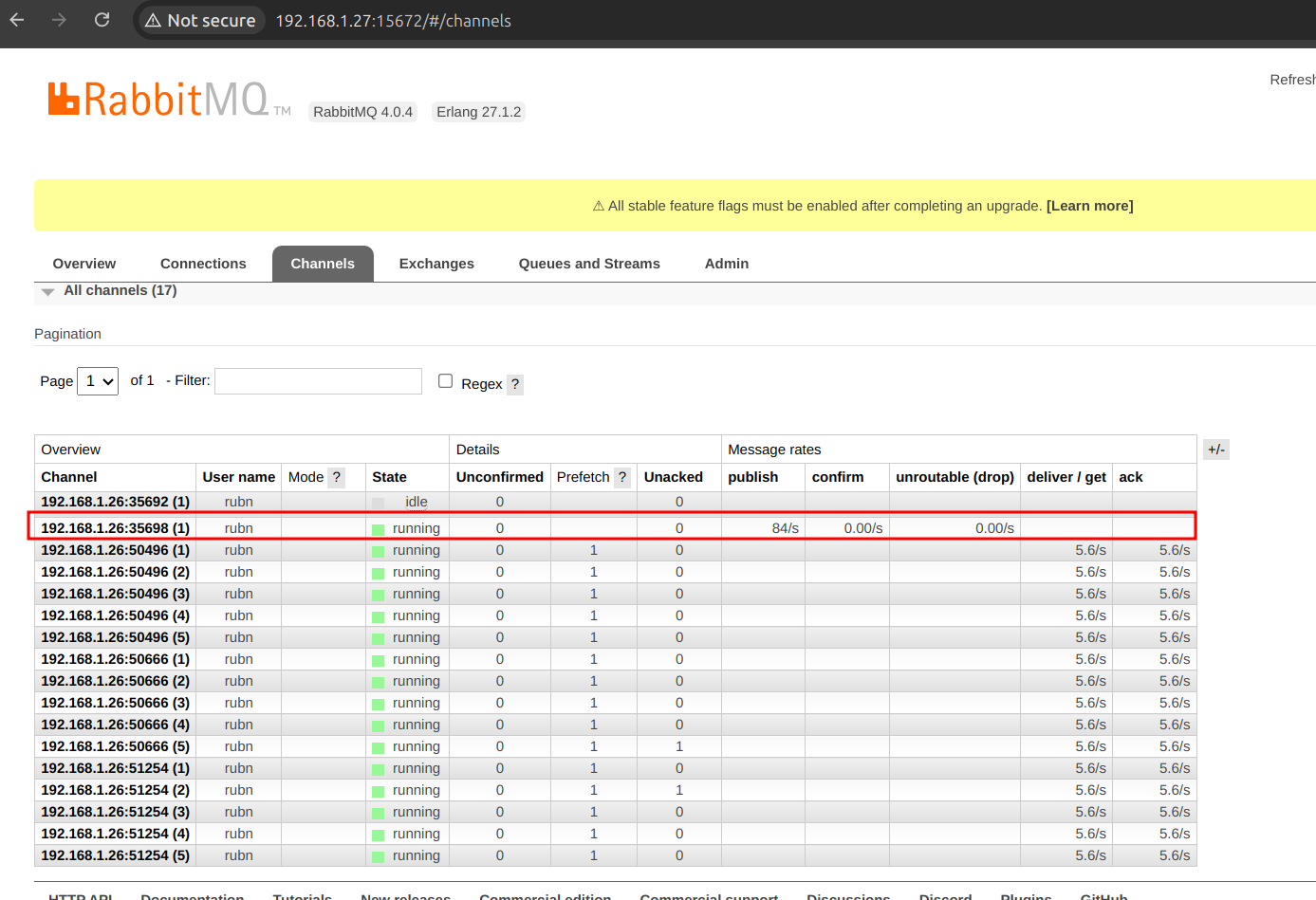
| Aquí ya se aprecia que cuando aumentamos los Threads se creas mas conexiones. |
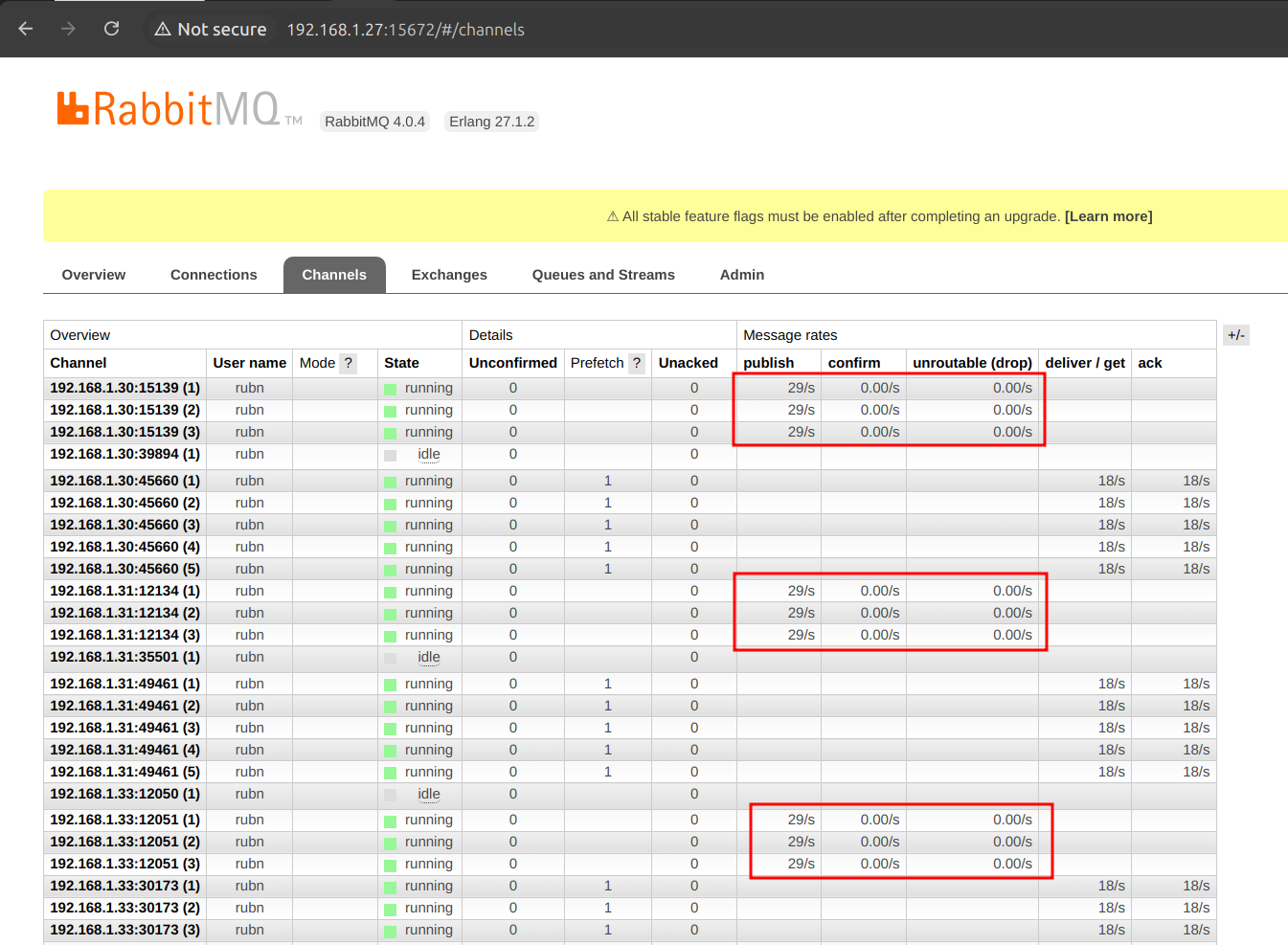
El consumidor no se le aplica un Thread/ThreadPool explicito como tal, sino que por medio de la configuración del SCS(spring cloud stream) aumentamos la concurrencia, por ejemplo:
spring:
cloud:
function:
definition: consumer
stream:
default-binder: rabbit
rabbit:
bindings:
consumer-in-0:
consumer:
prefetch: 1
binders:
rabbit:
type: rabbit
environment:
spring:
rabbitmq:
host: ${URL_BROKER}
port: 5672
username: ${USER}
password: ${PASSWORD}
bindings:
consumer-in-0: # Canal de entrada (Consumidor)
destination: performance-queue
group: my-consumer-group
consumer:
concurrency: 5 # Número de consumidores concurrentes (1)
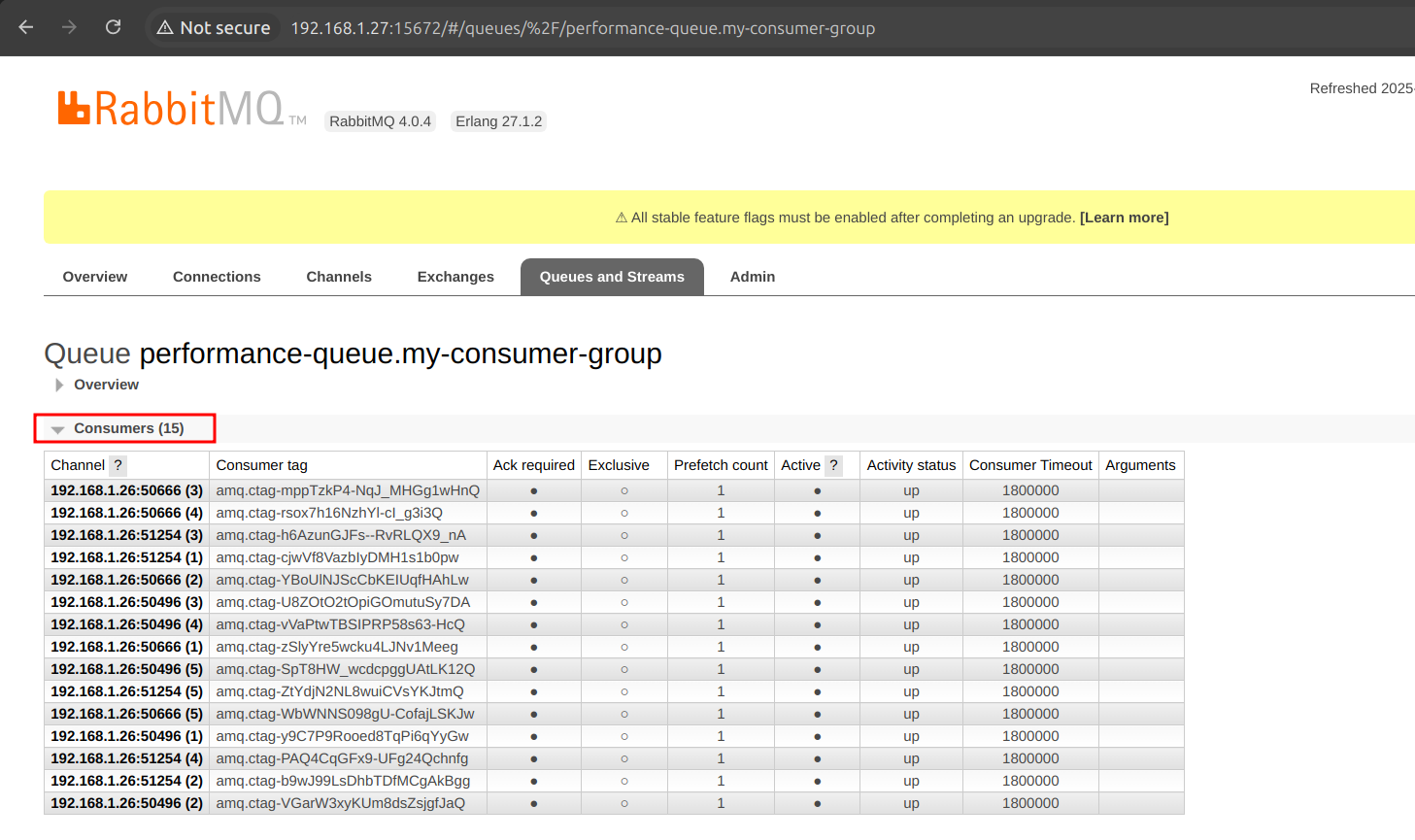
prefetch: 1| 1 | Aquí incrementamos la concurrencia como tal, y en la UI de Rabbit se verán la cantidad de consumidores, claramente tenemos 5, pero si tenemos 3 réplicas, 15 que se van a crear, como en la imagen siguiente: |
Para crear las instancias con este Bastillefile será un pelin más rápido, para un entorno de de developers con java.
PKG -y bash zip unzip curl git nano tmux
# jails.conf
CONFIG set allow.mlock;
CONFIG set allow.raw_sockets;
SYSRC defaultrouter="192.168.1.1"
# Install zsh
PKG zsh
CMD chsh -s /usr/local/bin/zsh root
PKG ohmyzsh
CMD cp /usr/local/share/ohmyzsh/templates/zshrc.zsh-template ~/.zshrc
# zsh-autosuggestions
PKG powerline-fonts zsh-autosuggestions
CMD echo 'source /usr/local/share/zsh-autosuggestions/zsh-autosuggestions.zsh' >> ~/.zshrc
# Install openjdk
PKG openjdk11 openjdk17 openjdk21
# Install sdkman
CMD curl -s "https://get.sdkman.io" | bash
CMD /usr/local/bin/zsh -c "echo 'export SDKMAN_DIR="$HOME/.sdkman"' >> ~/.zshrc"
CMD /usr/local/bin/zsh -c "echo '[[ -s "$HOME/.sdkman/bin/sdkman-init.sh" ]] && source "$HOME/.sdkman/bin/sdkman-init.sh"' >> ~/.zshrc"
# Copy available openjdk to candidates and then remove it
CMD mkdir -p ~/.sdkman/candidates/java
CMD cp -r /usr/local/openjdk11 ~/.sdkman/candidates/java/11
CMD cp -r /usr/local/openjdk17 ~/.sdkman/candidates/java/17
CMD cp -r /usr/local/openjdk21 ~/.sdkman/candidates/java/21
# Create symbolic links before removing packages
CMD ln -s ~/.sdkman/candidates/java/11/bin/java /usr/local/openjdk11/java
CMD ln -s ~/.sdkman/candidates/java/11/bin/javac /usr/local/openjdk11/javac
CMD ln -s ~/.sdkman/candidates/java/17/bin/java /usr/local/openjdk17/java
CMD ln -s ~/.sdkman/candidates/java/17/bin/javac /usr/local/openjdk17/javac
CMD ln -s ~/.sdkman/candidates/java/21/bin/java /usr/local/openjdk21/java
CMD ln -s ~/.sdkman/candidates/java/21/bin/javac /usr/local/openjdk21/javac
CMD pkg remove -y openjdk11 openjdk17 openjdk21
CMD /usr/local/bin/zsh -c "source \$HOME/.sdkman/bin/sdkman-init.sh && sdk install maven"
CMD /usr/local/bin/zsh -c "source \$HOME/.sdkman/bin/sdkman-init.sh && sdk install jbang"
CMD /usr/local/bin/zsh -c "source \$HOME/.zshrc"
# Set default java version to 21
CMD /usr/local/bin/zsh -c "source \$HOME/.sdkman/bin/sdkman-init.sh && sdk default java 21"
CMD /usr/local/bin/zsh -c "rehash"|
tmux en nuetra ayuda por usar muchas ventanas
|
El problema
3 instancias escribiendo en un fichero una latencia(puede ser cualquier cosa), por ejemplo, pero cuando se realiza la escritura, algo pasa entre líneas como:
| Estas fueron las latencias iniciales, ya no 😂 |
Por más que cada instancia tenga su lock propio, igualmente podrían interfieren en cierto punto como los casos de arriba, que no se si considerarla un race-condition (no creo este caso), pero igualmente se produce ese side efect, el método write del BuffereWriter contienen internamente en la jdk11 un synchronize propio como este en la clase Writer:
public void write(String str, int off, int len) throws IOException {
synchronized (lock) {
char cbuf[];
if (len <= WRITE_BUFFER_SIZE) {
if (writeBuffer == null) {
writeBuffer = new char[WRITE_BUFFER_SIZE];
}
cbuf = writeBuffer;
} else { // Don't permanently allocate very large buffers.
cbuf = new char[len];
}
str.getChars(off, (off + len), cbuf, 0);
write(cbuf, 0, len);
}
}Instalando Servidor Redis

Redis tiene un cliente llamado Redisson, para manipular/abstraer todas las estructuras relacionadas con redis, una de ellas es el uso del RLock que nos servira para probar en este caso y poder remediar nuestra issue de concurrencia a la hora de escribir
Con este Bastillefile, lo instalamos
# Install redis
PKG redis
SYSRC redis_enable="YES"
CONFIG set allow.mlock;
CONFIG set allow.raw_sockets;
SYSRC defaultrouter="192.168.1.1"
CMD redis-cli ping (1)| 1 | Esto debe responder PONG en la consola |
Vamos editar el fichero redis.conf que esta en la ruta /usr/local/etc/redis.conf
bind * -::*
requirepass ultrapassword
service redis restart (1)| 1 | Si que fue necesario reiniciar. |
Config para Redisson

la config que vamos usar en el consumer es la siguiente:
@Configuration
public class ReddisonClientConfiguration {
@Bean
public RedissonClient redissonClient(RedissonCredentialsConfiguration credentialsConfiguration) {
Config config = new Config();
config.useSingleServer().setAddress(credentialsConfiguration.getUrl());
config.useSingleServer().setPassword(credentialsConfiguration.getPassword());
return Redisson.create(config);
}
}| Ahora con el RLock para la sección critica practicamente la mísma historia que con el StampedLock pinta un poco mejor la cosa: |
private void writeLine(BufferedWriter writer, long latency) throws IOException {
final RLock lock = redissonClient.getLock("logFileLock");
lock.lock();
try {
//HH:mm;latency
final String line = FORMATER.format(LocalTime.now()) + ";" + latency;
writer.write(line);
writer.newLine();
} finally {
lock.unlock();
}
}
Ese video fue enviando 100 m/s mensajes por segundo
|
{
"values": [
{
"dato": 1,
"doc_count": 6000
},
{
"dato": 2,
"doc_count": 6000
},
{
"dato": 3,
"doc_count": 6000
},
{
"dato": 4,
"doc_count": 6000
},
{
"dato": 5,
"doc_count": 6000
},
{
"dato": 6,
"doc_count": 6000
},
{
"dato": 7,
"doc_count": 6000
},
{
"dato": 8,
"doc_count": 6000
},
{
"dato": 9,
"doc_count": 6000
},
{
"dato": 10,
"doc_count": 6000
}
]
}No se aprecia solape, o líneas raras en el ficherito .txt nada mal creo yo, también que si la cosa se complica mucho, cada instancia puede escribir en su propio fichero.
Evitando contención en el main-thread
Bien, esta parte también es lo más dura de la prueba, al introducir threads y de paso que se nos ocurra añadir un Thread.sleep(), y luego peor aún, esperar buen o regular rendimiento y más en una app low latency regulera.
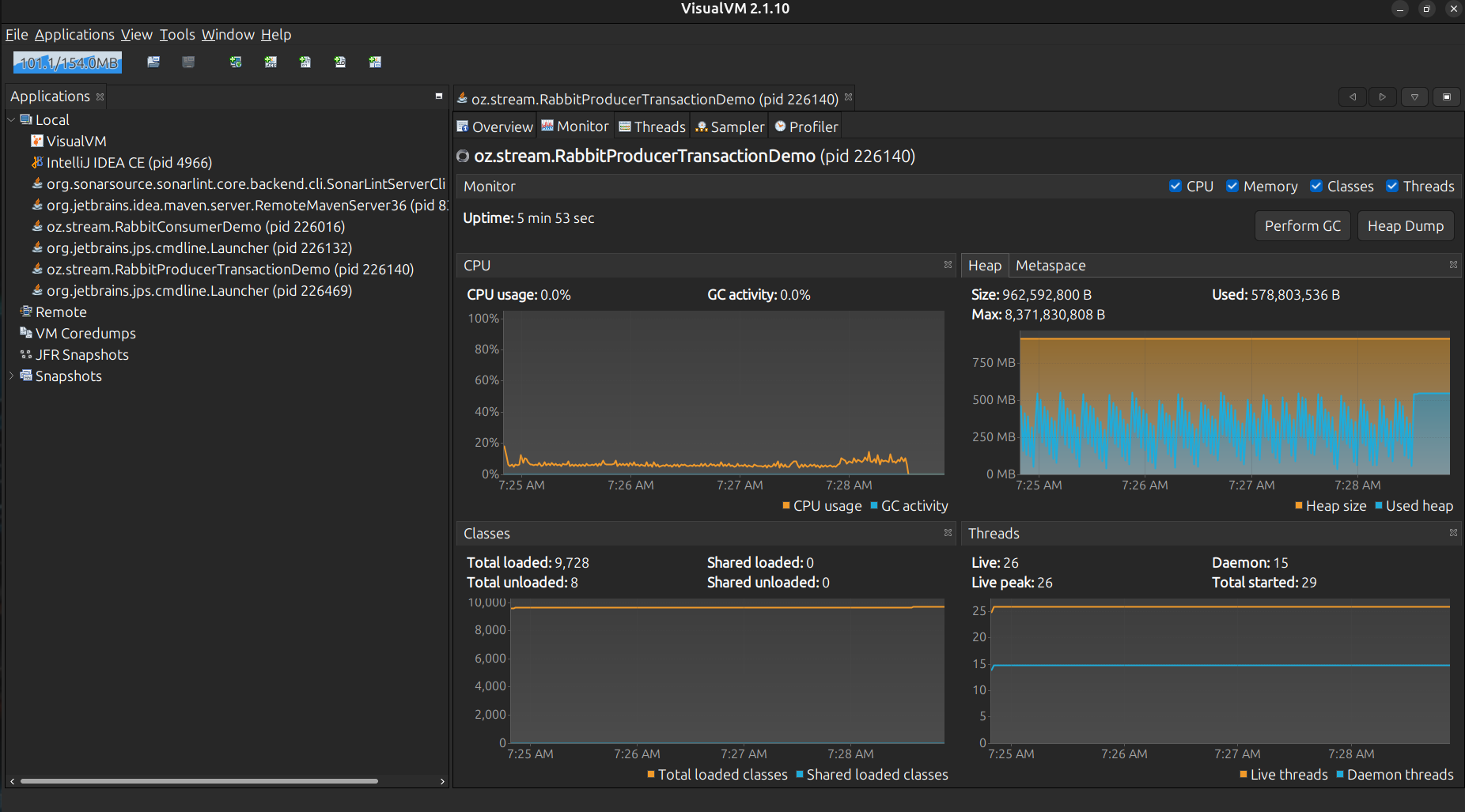
El código anterior, teníamos Thread.sleep() justo en el hilo principal para ajustar la tasa de mensajes, cada thread pausado por eso, colocandolo en estado de sleeping a running y viceversa, estos estados como Park, Running, Wait, Monitor, Sleeping, podemos verlos más comodamente con la JVisualVM, la Java-Mision-Control muy recomendada igualmente.
La idea es ajustar nuestra app, visualizando su comportamiento en tiempo real, y mirar como se comportan los threads, el sleep() es bloqueante y simplemente añade contención, reduciendo el rendimiento throughput a la larga por ejemplo:
Observando algunos enfoques
Estas pruebas, dependiendo el entorno pueden variar mucho, dado que se envían mensajes de distintos tamaños, el hardware etc…
Por parte del productor:
-
Mensajes de 200KiB.
-
3 Threads.
-
Se debe enviar 100msg/sec.
Por parte del consumidor:
-
Carga en memoria y luego escribiendo en disco cuando finalize el envío por parte del productor.
-
15 Threads.
sendMessage con Thread.onSpinWait()
for (int index = 0; index < totalDocCountToProcess; index++) {
// Intentamos obtener el siguiente slot de tiempo disponible
// mantiene ritmo global entre Threads, sin context switching
long currentSlot;
long nextSlot;
do {
currentSlot = lastGlobalSendTime.get();
nextSlot = currentSlot + globalDelayPerMessage;
} while (!lastGlobalSendTime.compareAndSet(currentSlot, nextSlot)); //CAS
// Esperamos hasta que sea nuestro turno
while (System.nanoTime() < nextSlot) {
Thread.onSpinWait();
}
Message<MessageDto> messageToSend = MessageBuilder.withPayload(messageDto)
.setHeader("timestamp_ms", System.currentTimeMillis())
.build();
this.streamBridge.send(PERFORMANCE_QUEUE, messageToSend);
COUNTER.incrementAndGet();
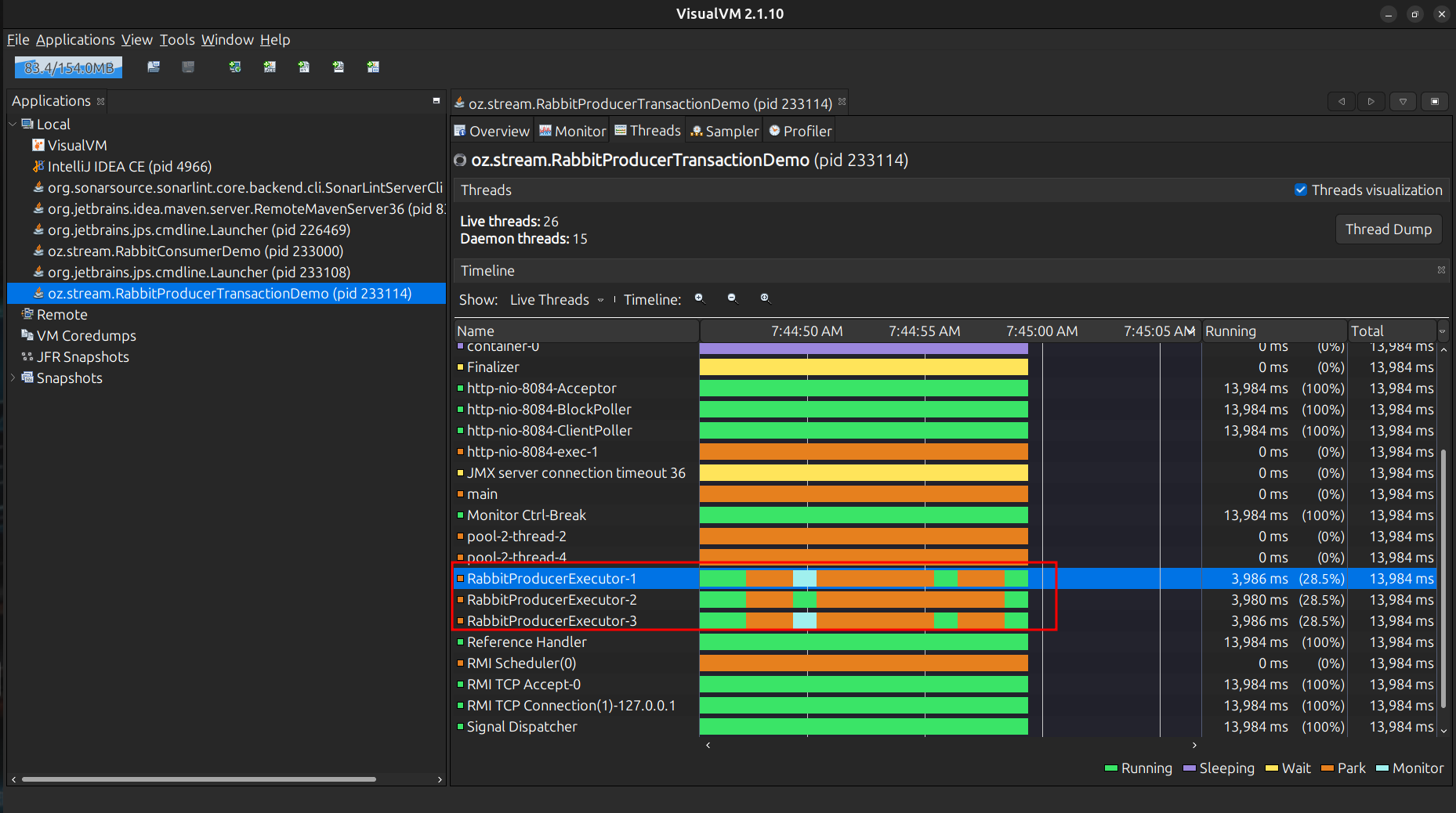
}Aquí se aprecian 3 Threads llamados RabbitProducerTaskExecutor-N, y siempre estarán en running es lo ideal, los pequeños
delay son aplicados con onSpinWait y un AtomicLong, aumentando el rendimiento considerablemente, y haciendo que se envíe
una tasa de mensajes/message rate, mas estable y precisa
Con este enfoque, los 100msg/sec son mas estables.
sendMessage con Thread.sleep()
for (int index = 0; index < totalDocCountToProcess; index++) {
Message<MessageDto> messageToSend = MessageBuilder.withPayload(messageDto)
.setHeader("timestamp_ms", System.currentTimeMillis())
.build();
this.streamBridge.send(PERFORMANCE_QUEUE, messageToSend);
COUNTER.incrementAndGet();
try {
Thread.sleep(TimeUnit.NANOSECONDS.toMillis(globalDelayPerMessage)); (1)
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}| 1 | Los nanos los pasamos a millis que es lo que necesita el sleep() |
Se aprecia que ahora los Threads estan más en sleeping que en running, y alguna que otra vez, pasan a estado de running pero muy poco, esto es igual a poco rendimiento y no estable con el onSpinWait o espera activa, busy-waiting.
Con el sleep() para llegar a los 100msg/sec le cuesta mucho
sendMessage con schedule()
@Configuration
public class SpringAsyncConfig {
private static final AtomicInteger THREAD_COUNTER = new AtomicInteger();
@Bean
public ScheduledExecutorService scheduledExecutorService(AppConfiguration configuration) {
final ThreadFactory threadFactory = runnable -> {
final Thread thread = new Thread(runnable);
thread.setName("RabbitProducerExecutor-" + THREAD_COUNTER.incrementAndGet());
return thread;
};
return Executors.newScheduledThreadPool(configuration.getCorePoolSize(), threadFactory);
}
}...
final CountDownLatch countDownLatch = new CountDownLatch((int) totalMessages);
for (int index = 0; index < numThreads; index++) {
// Si hay resto, algunos threads envían un mensaje extra
final long messagesForThisThread = messagesPerThread + (index < remainder ? 1 : 0);
scheduledExecutorService.schedule(() -> {
this.sendMessage(globalDelayPerMessage, messagesForThisThread, message, countDownLatch);
}, 0, TimeUnit.MICROSECONDS); (1)
}
try {
countDownLatch.await();
} catch (InterruptedException ex) {
throw new RuntimeException(ex);
}
log.info("Envío completado. Tiempo total: {} Total docCount: {}", responseTimeService.formatResponseTime(), COUNTER.get());
...
for (int index = 0; index < totalDocCountToProcess; index++) {
this.scheduledExecutorService.schedule(() -> {
Message<MessageDto> messageToSend = MessageBuilder.withPayload(messageDto)
.setHeader("timestamp_ms", System.currentTimeMillis())
.build();
this.streamBridge.send(PERFORMANCE_QUEUE, messageToSend);
COUNTER.incrementAndGet();
countDownLatch.countDown();
}, globalDelayPerMessage * index, TimeUnit.NANOSECONDS); (2)
}| 1 | En cero, para que se dispare rapidamente la tarea. |
| 2 | Aquí, si seteamos el delay y lo multiplicamos por cada indice. |
Con el newScheduledThreadPool se aprecia un rendimiento superior a la versión donde usamos el sleep(), y los estados de los Threads varian un poco más, de Running a Sleeping, Monitor, hasta Park también, siendo el código un pelin mas simple que usndo CAS + onSpinWait()
sendMessage con un stream reactivo
public Scheduler scheduler() {
final AtomicInteger atomicInteger = new AtomicInteger(0);
final ThreadFactory threadFactory = runnable -> {
final Thread thread = new Thread(runnable);
thread.setName("RabbitProducerMessage-" + atomicInteger.incrementAndGet()); (1)
return thread;
};
return Schedulers.fromExecutor(Executors.newFixedThreadPool(3, threadFactory));
}| 1 | El nombre customizado de nuestro Thread, RabbitProducerMessage- |
@Test
@SneakyThrows
@DisplayName("Emitimos 30 items/mensajes en total")
void reactiveMessageSenderStepVerifier() {
final var counter = new AtomicInteger(0);
StepVerifier.create(Flux.range(0, 3)
.publishOn(this.scheduler())
.flatMap(mapper -> Flux.range(0, 10)
.delayElements(Duration.ofMillis(33))
.publishOn(this.scheduler())
.doOnNext(onNext -> {
counter.incrementAndGet();
log.info("Send message {}", "ABC");
})
))
.expectNextCount(30) (1)
.verifyComplete();
}| 1 | Nos aseguramos de emitir 30 items/mensajes de prueba, para asegurarnos de que el stream reactivo funcione como debe. |
@Configuration
public class SpringAsyncConfig {
@Bean
public Scheduler scheduler(AppConfiguration configuration) {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(configuration.getCorePoolSize()); // Minimum number of threads in the pool
executor.setThreadNamePrefix("RabbitProducerTaskExecutor-"); // Prefix for thread names
executor.initialize(); // Initializes the thread pool
return Schedulers.fromExecutor(executor);
}
}Flux.range(0, numThreads)
.flatMap(index -> {
final long messagesForThisThread = messagesPerThread + (index < remainder ? 1 : 0);
return this.sendMessage(globalDelayPerMessage, messagesForThisThread, message, countDownLatch);
})
.subscribe();
try {
countDownLatch.await();
} catch (InterruptedException ex) {
throw new RuntimeException(ex);
}
log.info("Envío completado. Tiempo total: {} Total docCount: {}", responseTimeService.formatResponseTime(), COUNTER.get());private Mono<Void> sendMessage(final long globalDelayPerMessage, final long totalDocCountToProcess,
String messagePayload, final CountDownLatch countDownLatch) {
log.info("Iniciando envío de {} mensajes con un delay de {} ms", totalDocCountToProcess, TimeUnit.NANOSECONDS.toMillis(globalDelayPerMessa
MessageDto messageDto = new MessageDto();
messageDto.setMessage(messagePayload);
return Flux.range(0, (int) totalDocCountToProcess)
.delayElements(Duration.ofMillis(globalDelayPerMessage))
.publishOn(this.scheduler) (1)
.doOnNext(this.getTimestampMs(messageDto))
.then()
.doOnTerminate(countDownLatch::countDown);
}
private Consumer<Integer> getTimestampMs(MessageDto messageDto) {
return onNext -> {
Message<MessageDto> messageToSend = MessageBuilder.withPayload(messageDto)
.setHeader("timestamp_ms", System.currentTimeMillis())
.build();
this.streamBridge.send(PERFORMANCE_QUEUE, messageToSend);
COUNTER.incrementAndGet();
};
}| 1 | Estos items cambiamos su ejecución en el executor nuestro customizado. |
Aquí la cosa varia un poco, con el operador range, iteramos también por el número de threads actuales, importante el operador publishOn para ejecutar los items internos en el executor nuestro customizado.
Mensajes de 2MiB
Se ven diferencias aquí, pero el consumo de CPU no es tanto por lo visto.
Ya con mensajes más pesados de 2MiB con el onSpintWait, sufre también
Incluso vemos en consola
Envío completado. Tiempo total: 5(min) 329(sec) 329349(ms) 2147483647(nanos) Total docCount: 18000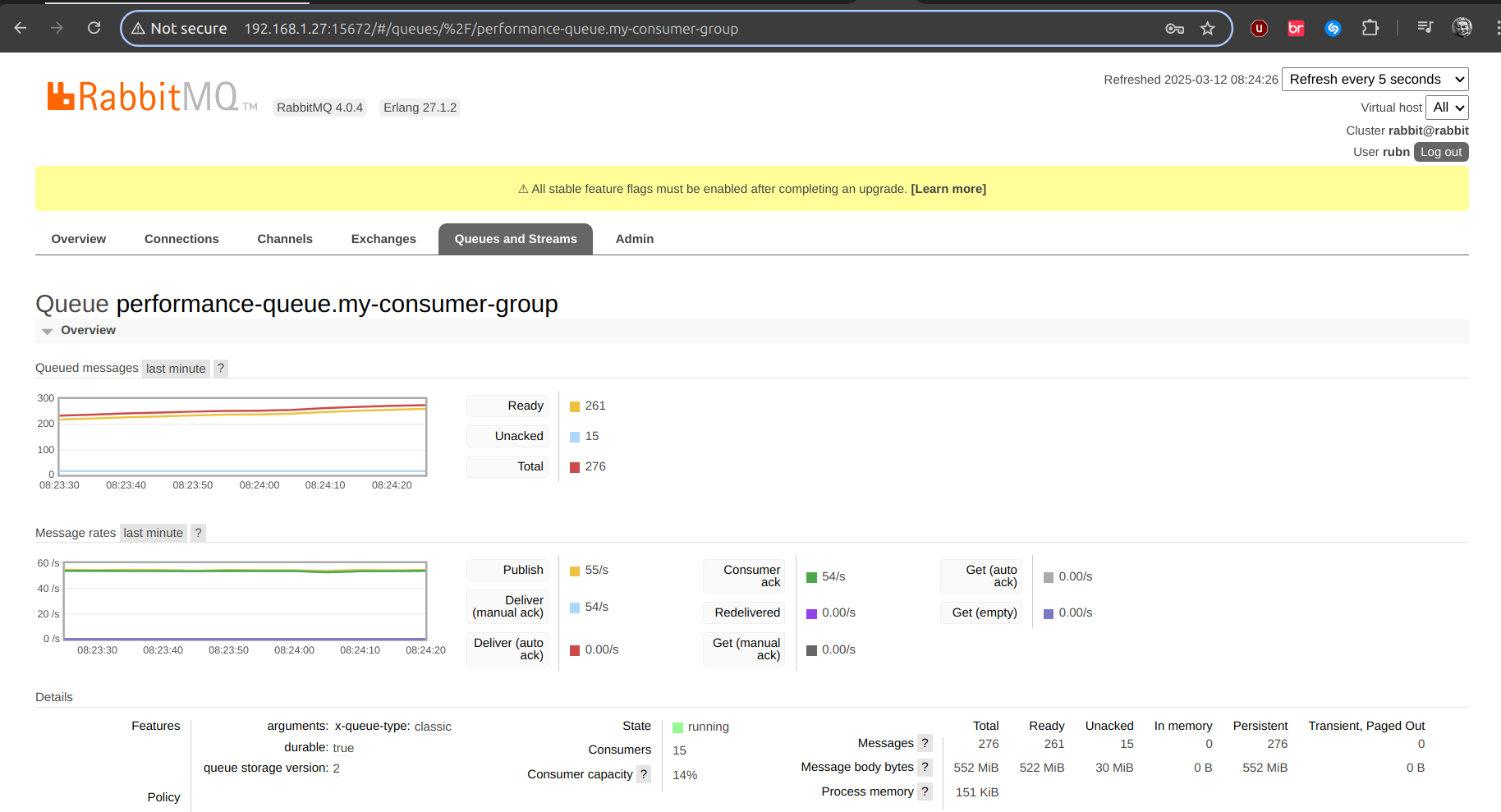
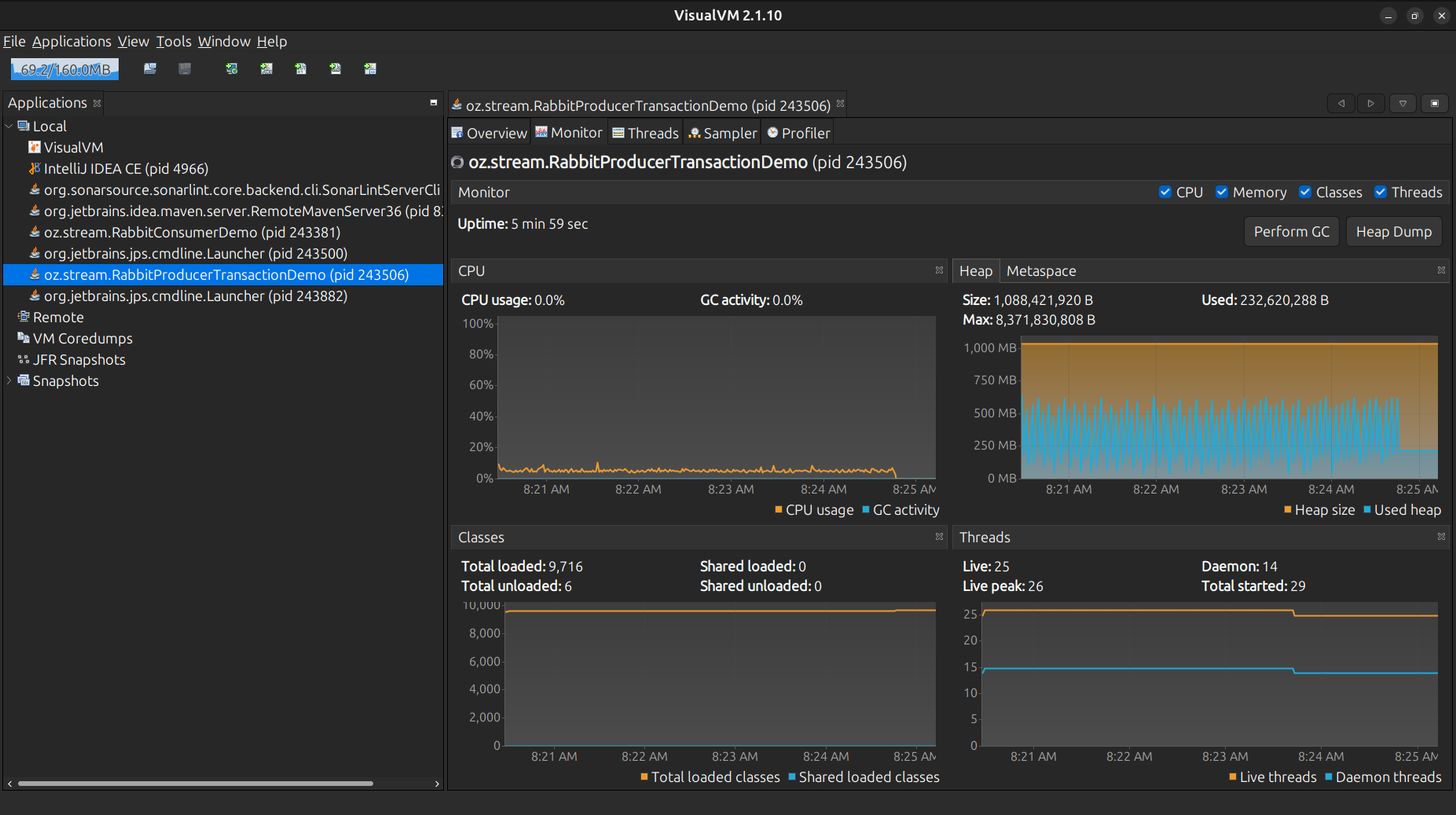
Ya aquí la cantidad de encolados es superior, y en aumento…
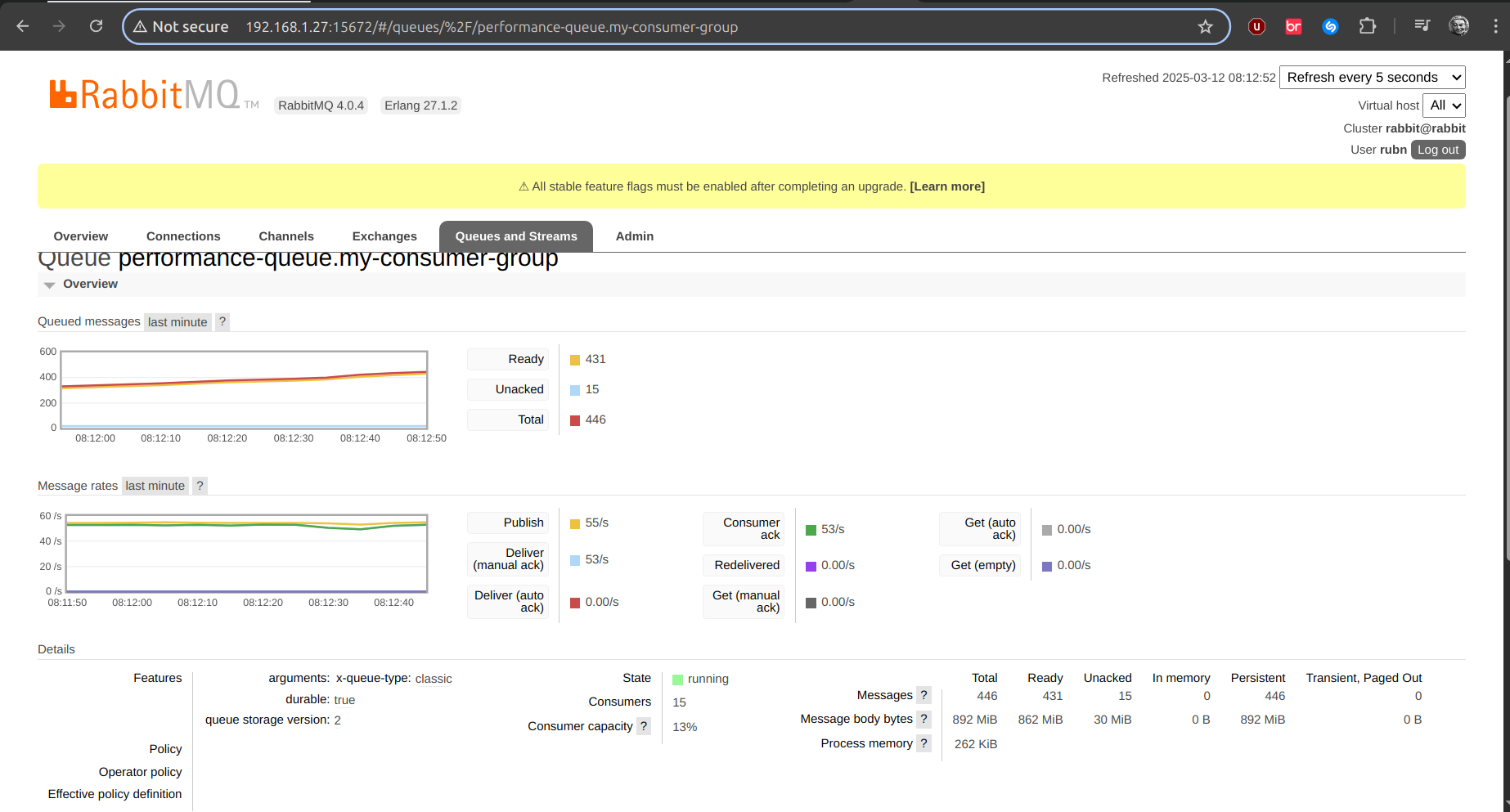
Consumo de CPU
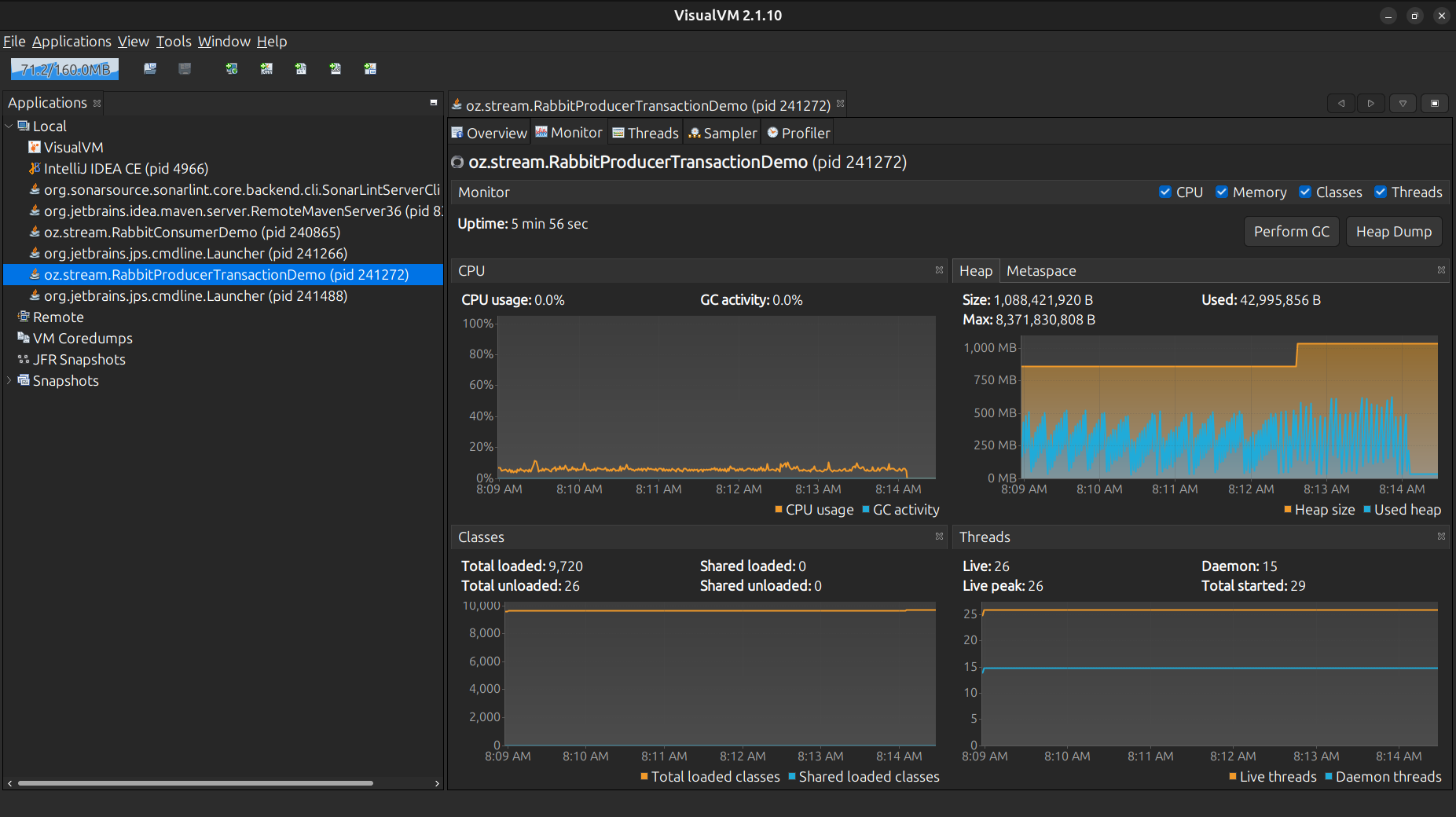
Con el ScheduledExecutorService se aprecia mayor mensajes encolados
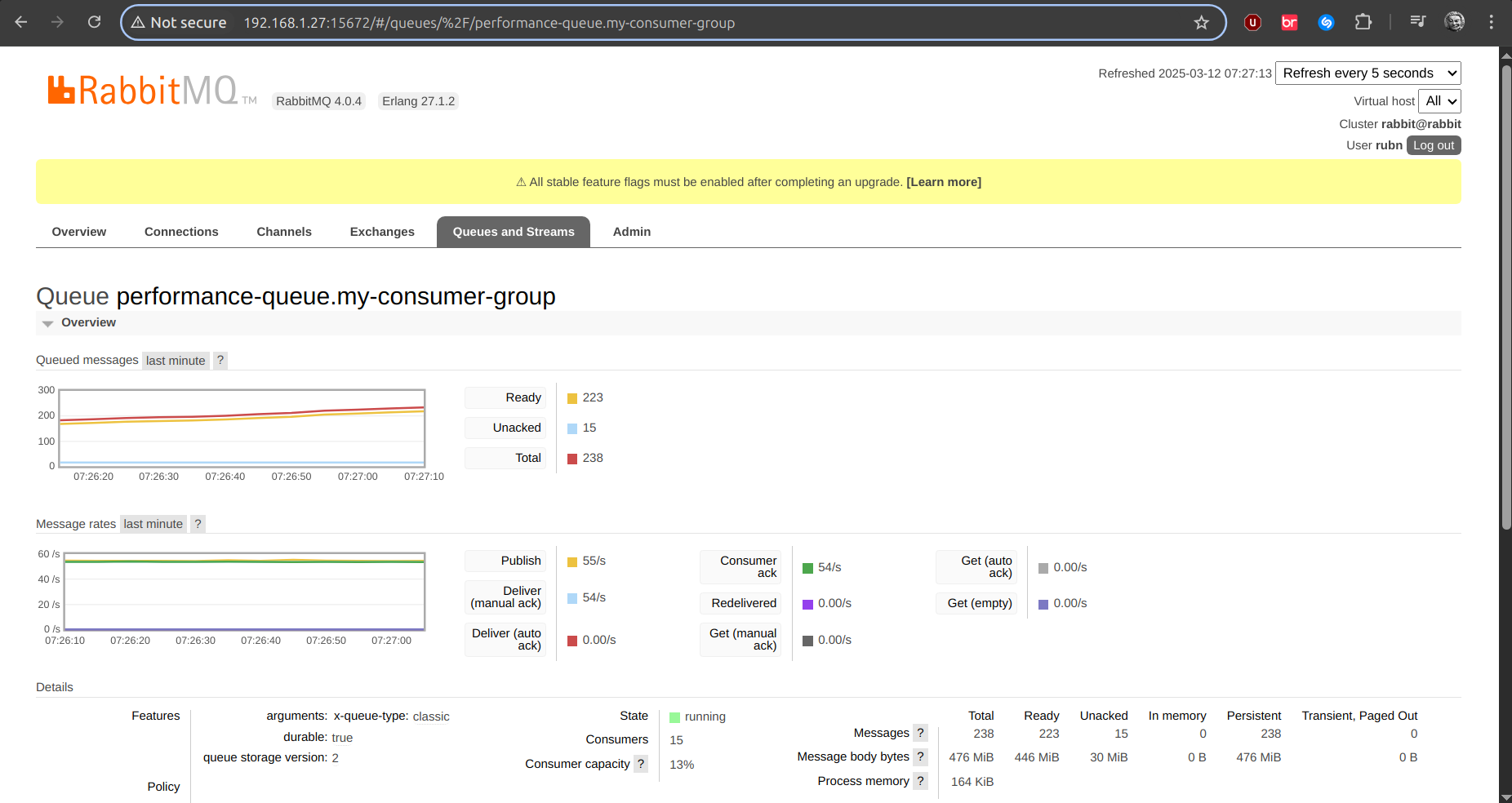
Consumo de CPU