
Un simple ejemplo donde se usa el api Stream de java, para extraer las
palabras y contar el numero de repeticiones, para ello usamos una
función para eliminar los caracteres en este caso serán, [.,!] y
caracter de espaciado uno solo así " " más los Strings que sean
empty así "", que debemos filtrar si o si.
private String normalize(final String word) {
return word.toLowerCase().replaceAll("[\\.\\,\\!]", ""); (1)
}| 1 | La expresión regular que se me ocurrió es esta [\\.\\,\\!] usando
doble backslash, todas los matches de puntos, comas, exclamación,
también las convertiremos en minúsculas, con toLowerCase junto con
el método replaceAll |
|
Nuestro texto objetivo es el siguiente:
Hola que tal, bienvenidos a BettaTech, Si os está gustando este video, suscribiros y darle a la campanita para ver los nuevos videos que vaya subiendo! |
final String[] words = "Hola que tal,
" bienvenidos a BettaTech, Si os está gustando " +
"este vídeo, suscribiros y darle a la campanita" +
" para ver los nuevos videos que vaya subiendo!".split(" "); (1)| 1 | Este String lo introducimos en un array de String e invocamos al método split, con un caracter en blanco como parámetro, para que después de cada
espacio almacene cada palabra en una posición de nuestro array. |
System.out.printf("%-15s%s%n","Word","Frecuency"); (1)| 1 | Imprimimos con printf un formateo de 15 caracteres de espaciado |
.filter(this::filterEmptyAndNull) (1)| 1 | Invocamos al método filter del Stream, la fase de filtrado para
los carácteres empty y null de nuestro String, para compactar más el
código, pasaremos el propio método por referencia
method reference :: |
private boolean filterEmptyAndNull(final String word) {
return Objects.nonNull(word) && !"".equals(word);
}.map(this::normalize) (1)| 1 | La función map, que es la fase de mapping del stream, en este caso
hacemos un method::reference ya que el método normalize es una
función con un parámetro y retorna un objeto, encajando en nuestro map
perfectamente. |
.collect(Collectors.groupingBy(e -> e,Collectors.counting())) (1)| 1 | Hacemos una reducción mutable a este Stream con collect, donde el
método groupingBy le dice al collect que debe agrupar todos los
elementos en un Map, el primer parámetro es que retorne el mismo valor
pasado en la expresión lambda siendo una operación muy común podríamos
usar tanto e -> e como Function.identity(), el segundo parámetro
es un downstream collector `Collectors.counting()`que nos permitirá
contar los elementos repetidos, permitiendo crear el value de cada key. |
package com.test.frencuencywords.service;
import lombok.NonNull;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.Arrays;
import java.util.Map;
import java.util.Objects;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.Stream;
/**
* @author rubn
*/
@Service
public class FrecuencyWordsService {
private static final String REG_EXP = "[\\.\\,\\!]";
private static final String SPLIT_ESPACE_CARACTER = " ";
/**
*
* Process with parallelStream()
*
* @param words to count
* @return Map<String,Long> with key(word), and value(frecuency)
*/
public Map<String,Long> frecuencyWordsParallel(@NonNull final String words) {
final String[] splitWords = words.split(SPLIT_ESPACE_CARACTER);
return Arrays.stream(splitWords)
.parallel() (1)
.filter(this::filterEmptyAndNull)
.map(this::normalize)
.collect(Collectors.groupingBy(Function.identity(),Collectors.counting()));
}
/**
*
* Process with stream()
*
* @param words to count
* @return Map<String,Long> with key(word), and value(frecuency)
*/
public Map<String,Long> frecuencyWords(@NonNull final String words) {
final String[] splitWords = words.split(SPLIT_ESPACE_CARACTER);
return Arrays.stream(splitWords)
.filter(this::filterEmptyAndNull)
.map(this::normalize)
.collect(Collectors.groupingBy(Function.identity(),Collectors.counting()));
}
/**
*
* @param input path
* @return Map<String,Long> with key(word), and value(frecuency)
*/
public Map<String,Long> frecuencyWordsFromFile(final Path input) { (2)
try (final Stream<String> lines = Files.lines(input)) { (3)
return Arrays.stream(lines.collect(Collectors.joining()) (4)
.split(SPLIT_ESPACE_CARACTER))
.filter(this::filterEmptyAndNull)
.map(this::normalize)
.collect(Collectors.groupingBy(Function.identity(),Collectors.counting()));
} catch (IOException ex) {
throw new RuntimeException(ex);
}
}
private boolean filterEmptyAndNull(final String word) {
return Objects.nonNull(word) && !"".equals(word);
}
private String normalize(final String word) {
return word.toLowerCase().replaceAll(REG_EXP, "");
}
}| 1 | Usando el método parallel, muchas veces esto no dan un incremento en el performance notable, rara vez se usa. |
| 2 | Usamos el parametro path que contendra la ruta del input o fichero en este caso, que queremos leer. |
| 3 | Usamos el metodo lines, para leer el path y obtener un Streams de Strings, algo especial es que no carga todo el contenido en memoria 🥰. |
| 4 | Recolectamos todo el Stream de Strings en un String. |
Test final y también con lectura de archivo que contiene el mismo texto target
package com.test.frencuencywords;
import com.test.frencuencywords.service.FrecuencyWordsService;
import com.test.frencuencywords.util.Memory;
import lombok.extern.log4j.Log4j2;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit.jupiter.SpringExtension;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.Map;
import java.util.stream.Collectors;
import static org.assertj.core.api.AssertionsForInterfaceTypes.assertThat;
/**
* @author rubn
*
* Simple test for frecuency words
*/
@Log4j2
@ExtendWith(SpringExtension.class)
@ContextConfiguration(classes = {FrecuencyWordsService.class,Memory.class})
@DisplayName("Frecuency words, reading text, sync, async from String or File")
class FrecuencyTest {
private static final String FORMAT_PRINTF_15 = "%-15s%s";
private static final String WORD = "Word";
private static final String HOLA = "hola";
private static final String FRECUENCY = "Frecuency";
private static final Path PATH_TEXT_FILE = Path.of("src/test/resources/textoSimple.txt");
@Autowired
private FrecuencyWordsService frecuencyWordsService;
@Autowired
private Memory memory;
private final String WORDS = "Hola que tal, bienvenidos a BettaTech, Si os está gustando este vídeo, suscribiros y darle a la campanita para ver los nuevos videos que vaya subiendo!";
@Test
@DisplayName("reading text from String text with blockingIO")
void testFrecuencyWordsNull() {
log.info("Run Frecuency");
log.info(String.format(FORMAT_PRINTF_15,WORD,FRECUENCY));
final Map<String,Long> mapWordsSync = frecuencyWordsService.frecuencyWords(WORDS);
Assertions.assertNotNull(mapWordsSync);
mapWordsSync.forEach((word, frecuency) -> { (1)
log.info(String.format(FORMAT_PRINTF_15, word, frecuency));
});
final long actual = mapWordsSync.get(HOLA);
final long expected = 1;
assertThat(actual).isEqualTo(expected);
/*
* total memory consumption
*/
log.info(memory.getTotalMemory());
}
@Test
@DisplayName("reading text from String text parallel")
void testFrecuencyWordsParallel() {
log.info("Run Frecuency Parallel");
log.info(String.format(FORMAT_PRINTF_15,WORD,FRECUENCY));
final Map<String,Long> mapWordsParallel = frecuencyWordsService.frecuencyWordsParallel(WORDS);
Assertions.assertNotNull(mapWordsParallel);
mapWordsParallel.forEach((word, frecuency) -> {
log.info(String.format(FORMAT_PRINTF_15, word, frecuency));
});
final long actual = mapWordsParallel.get(HOLA);
final long expected = 1;
assertThat(actual).isEqualTo(expected);
/*
* total memory consumption
*/
log.info(memory.getTotalMemory());
}
@Test
@DisplayName("reading text from input with 'BufferedReader' ")
void testFrecuencyWordsFromTextFile() {
if(Files.exists(PATH_TEXT_FILE)) {
log.info("Run Frecuency Parallel");
try (final InputStream inputStream = this.getClass().getResourceAsStream("/textoSimple.txt");
final Reader reader = new InputStreamReader(inputStream, StandardCharsets.UTF_8);
final BufferedReader br = new BufferedReader(reader)) {
final StringBuilder sb = new StringBuilder();
//read lines with Stream api
sb.append(br.lines().collect(Collectors.joining()));
final Map<String, Long> mapWordsParallel = frecuencyWordsService.frecuencyWords(sb.toString());
log.info(String.format(FORMAT_PRINTF_15,WORD,FRECUENCY));
mapWordsParallel.forEach((word, frecuency) -> {
log.info(String.format(FORMAT_PRINTF_15, word, frecuency));
});
final long result = mapWordsParallel.get(HOLA);
final long expected = 1;
assertThat(result).isEqualTo(expected);
} catch (IOException ex) {
log.error(ex.getMessage());
}
/*
* total memory consumption
*/
log.info(memory.getTotalMemory());
} else {
throw new RuntimeException("File not found!");
}
}
@Test
@DisplayName("reading text from input with 'Files.lines' ")
void frecuencyFromPath() {
log.info("Run Frecuency Parallel");
final Map<String,Long> mapWordsParallel = frecuencyWordsService.frecuencyWordsFromFile(PATH_TEXT_FILE);
log.info(String.format(FORMAT_PRINTF_15, WORD,FRECUENCY));
mapWordsParallel.forEach((word, frecuency) -> {
log.info(String.format(FORMAT_PRINTF_15, word, frecuency));
});
final long result = mapWordsParallel.get(HOLA);
final long expected = 1;
assertThat(result).isEqualTo(expected);
/*
* total memory consumption
*/
log.info(memory.getTotalMemory());
}
}| 1 | Recorriendo el stream con un forEach, pero como ya nuestro collect nos retorna un
Map<String,Long> el forEach de la interface Map, tiene un BiConsumer
como parámetro, y esta a su vez, el método accept, que tiene 2
parámetros genéricos, uno para la key y otro para el value,
forEach((key,value) -> {}) |
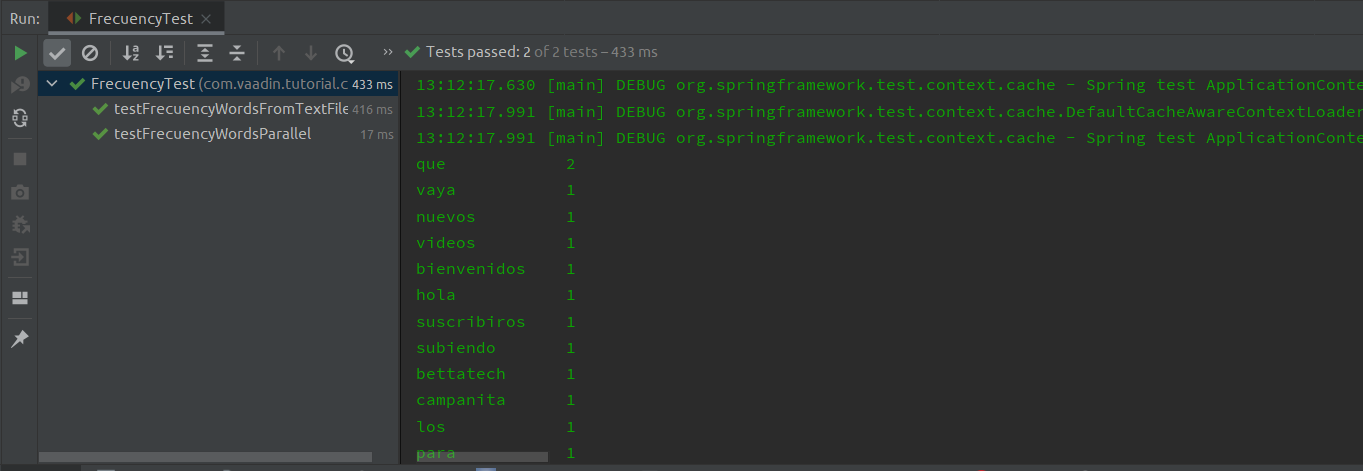
Salida en consola con el método usando streams parallel
15:35:14.030 [main] INFO com.test.frencuencywords.FrecuencyTest - Run Frecuency Parallel
15:35:14.035 [main] INFO com.test.frencuencywords.FrecuencyTest - Word Frecuency
15:35:14.035 [main] INFO com.test.frencuencywords.FrecuencyTest - darle 1
15:35:14.036 [main] INFO com.test.frencuencywords.FrecuencyTest - que 2
15:35:14.036 [main] INFO com.test.frencuencywords.FrecuencyTest - a 2
15:35:14.036 [main] INFO com.test.frencuencywords.FrecuencyTest - vaya 1
15:35:14.036 [main] INFO com.test.frencuencywords.FrecuencyTest - os 1
15:35:14.036 [main] INFO com.test.frencuencywords.FrecuencyTest - nuevos 1
15:35:14.036 [main] INFO com.test.frencuencywords.FrecuencyTest - videos 1
15:35:14.036 [main] INFO com.test.frencuencywords.FrecuencyTest - bienvenidos 1
15:35:14.036 [main] INFO com.test.frencuencywords.FrecuencyTest - hola 1
15:35:14.036 [main] INFO com.test.frencuencywords.FrecuencyTest - verlos 1
15:35:14.036 [main] INFO com.test.frencuencywords.FrecuencyTest - suscribiros 1
15:35:14.036 [main] INFO com.test.frencuencywords.FrecuencyTest - subiendo 1
15:35:14.036 [main] INFO com.test.frencuencywords.FrecuencyTest - bettatech 1
15:35:14.036 [main] INFO com.test.frencuencywords.FrecuencyTest - este 1
15:35:14.036 [main] INFO com.test.frencuencywords.FrecuencyTest - campanita 1
15:35:14.036 [main] INFO com.test.frencuencywords.FrecuencyTest - para 1
15:35:14.037 [main] INFO com.test.frencuencywords.FrecuencyTest - está 1
15:35:14.037 [main] INFO com.test.frencuencywords.FrecuencyTest - la 1
15:35:14.037 [main] INFO com.test.frencuencywords.FrecuencyTest - si 1
15:35:14.037 [main] INFO com.test.frencuencywords.FrecuencyTest - gustando 1
15:35:14.037 [main] INFO com.test.frencuencywords.FrecuencyTest - y 1
15:35:14.037 [main] INFO com.test.frencuencywords.FrecuencyTest - vídeo 1
15:35:14.037 [main] INFO com.test.frencuencywords.FrecuencyTest - tal 1
15:35:14.076 [main] INFO com.test.frencuencywords.FrecuencyTest - Total Memory 57MB (1)| 1 | Consumo total de memoria en ese momento, suele variar mucho dependiendo el hardware. |
Inpiración
Según esta pregunta se la hicieron a un doc para un entrevista,
donde resuelve este caso con TypeScript, nada fácil para resolver
así a primeras, porque siempre hay soluciones más eficientes que otras,
y este caso no es la excepción, porque mi ejemplo tengo 2 maneras más de
hacerlo con switch y for, en donde ambas soluciones incremento
posiciones.